
 ����Arm Cortex-M55��������AIָ��Uչ�c�����{�����`
�r�g��2025-04-23 ��Դ���A���hҊ
����Arm Cortex-M55��������AIָ��Uչ�c�����{�����`
�r�g��2025-04-23 ��Դ���A���hҊ
����
�S��߅��Ӌ������W��IoT���Ŀ��ٰlչ��Ƕ��ʽ�O�䌦�˹����ܣ�AI���͙C���W����ML����֧�������������L��Arm Cortex-M55 �������{��������ܡ����ĺ͌���AI�����������ɞ�߅��AI���õ����xƽ�_�����Č��������Cortex-M55��AIָ��Uչ�������� Helium �� AI-NPU�������Y�ό��H����̽ӑ�������{�������������_�l�߸�Ч�����@һ�ܘ����F߅��AI���á�
һ��Cortex-M55��AIָ��Uչ��Helium�cAI-NPU
1.1 Helium������Mϵ�е������Uչ
Helium��MVE��Matrix Vector Extension�� ��Arm��Cortex-Mϵ���OӋ��ȫ��SIMD����ָ���������ָ��Uչ��ּ�ڞ�Ƕ��ʽ�O���ṩ��Ч��AI����̖̎���������������������
· 150+��ָ�����130+ʸ��ָ�֧���������c�\�㡣
· 128λ�����Ĵ�����8�������Ĵ�����V0-V7����ÿ���Ĵ�����ӳ�䵽4��FPU�Ĵ�������������c��e������
· �������֧�֣�
o ������8�16�32�
o ���c���뾫�ȣ�FP16�����ξ��ȣ�FP32�����p���ȣ�FP64����
· �pģʽ�Uչ��
o MVE-I���H֧�������\�㡣
o MVE-F��֧���������c�\�㡣
����Neon��
Helium���Neon���p������ᘌ����Ĉ�����������֧��8λ�����Ͱ뾫�ȸ��c�\�㣬���m��AIģ���еľ��e������\��Ȳ�����

1.2 AI-NPU�������W�j������
Cortex-M55�ɼ��� AI-NPU���W�j̎��������ͨ�^Ӳ�������Mһ������AI�������ܡ��䃞�ݰ�����
· ����Ч�ȣ���ȼ�CPUӋ�㣬NPU�Ɍ�AI�����ٶ�����������ͬ�r�����ġ�
· ֧������ģ�ͣ�����TensorFlow Lite Micro��Arm Ethos-U NPU�ȿ�ܣ�����ģ�Ͳ���
· �`�����ã�������MAC��Ԫ�������ȴ控���ȅ������m�䲻ͬ��������
����Cortex-M55�ļܘ����c�c���܃���
2.1 ���ļܘ�
Cortex-M55���� ARMv8.1-M�ܘ������� 4�����������ˮ����֧�������P�I���ԣ�
· �pָ���a����ͬ�r��a�ɂ�������16λT16ָ�������������
· �f̎�����ӿڣ�֧���Զ��xָ��Uչ����AI-NPU���������`���ԡ�
· ���܌��ȣ�
o CoreMark/MHz��4.2����Cortex-M4��25%��������Cortex-M7�s20%��
o �l�ʣ���M4��15%����������ˮ���L�ȣ��o���cM7�ij������OӋƥ������
2.2 �����x�
Cortex-M55�ṩ��N���ã��_�l�߿ɸ��������x��
· ���A���ã��H������ˮ����
· FPU֧�֣����Ӹ��c�\��������
· Helium�Uչ������������MVE-I�������c������MVE-F������߽Y�ϡ�
���������{�����`
3.1 ������������Helium��
3.1.1 ����ָ���ʹ��
ͨ�^Helium��MVEָ��Ɍ������\���D�Q�������\�㣬�@���������������磬���D���ľ��e������
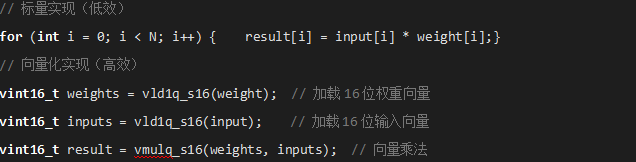
3.1.2 �ȴ挦�R�c�Aȡ����
· �������R���_�����������Ĕ����ڃȴ��Ќ��R��16�ֹ�߅�磬�������ܓpʧ��
· �Aȡָ�ʹ��PLD���Aȡ������ָ����ǰ���d���m�������p�پ������t��
3.2 AI-NPU�������c�{��
3.2.1 ģ�������c���s
· ��������FP32ģ���D�Q��INT8��FP16��ʽ�����̓ȴ�ռ�ú�Ӌ����s�ȡ�
· ��֦�c���s��ͨ�^ģ�͉��s���g�p�م��������m��߅���O����YԴ���ơ�
3.2.2 NPU�cCPU�fͬӋ��
· �΄շ��䣺�����sӋ�㣨����e�����oNPU������߉������CPU̎����
· �ȴ��������������NPU���Ãȴ棬���┵����CPU��NPU�g���l����ؐ��
3.3 �ܺă���
· �ӑB늉��c�l���{����DVFS��������ؓ�d�ӑB�{��CPU�l�ʺ�늉���ƽ�������c���ġ�
· ˯��ģʽ���ڷ�Ӌ���A���M�����ģʽ����Sleep-on-Exit����
�ġ����H����������Cortex-M55���Z���R�e����
4.1 ��������
����һ������ TensorFlow Lite Micro ���P�I�~�z�yģ�ͣ���“�����~�R�e”����Ҫ��
· ���ģ�����100mW��
· ���t��푑��r�g<50ms��
4.2 �������E
1. ģ��������
o ��FP32ģ���D�Q��INT8��ʽ���p�كȴ�ռ�á�
2. ���������٣�
o ʹ��Helium��MVE-Fָ�����̖�A̎������FFT����
3. NPU���٣�
o �����e�ӽ���NPU̎����CPUؓ؟�����A̎���ͺ�̎����
4. �ȴ惞����
o ʹ��SRAM�������g�Y���������l���L��Flash��
4.3 �Y��
· ���������������ٶ�����3�������Ľ���40%��
· 푑��r�g��������30ms�ԃȣ��M�㌍�r��Ҫ��
�塢���Y�cչ��
Cortex-M55ͨ�^ Helium�����Uչ �� AI-NPU����Ƕ��ʽAI�ṩ�ˏ���������c��Ч�ȡ��_�l����Y�����²��Ԍ��F�������
1. �������������ָ��p�٘����\�㡣
2. ��������NPU�cCPU���΄շֹ���ƽ���YԴ���á�
3. ��ȃ����ȴ��c���Ĺ������_�������t�c���ġ�
δ�����S�� Arm Ethos-U NPU ���Mһ�����ɺ���朵����ƣ�Cortex-M55����߅��AI�I��l�]���������ƄӸ����sģ�ͣ����p����CNN��Transformer�������
 �n�̷������A���hҊ��NXP�Ƴ�i.MX8M Plus�_�l�c���`�n�̷���������HarmonyOSϵ�y�����W�_�l�����n�̣��n�̷�����HaaS EDU K1�_�l�̳̣����n��ҕ�l��Դ�a���°�C�Z�Ծ���֮�����Z��ҕ�l�̳��ذ�ٛ�ͣ�Ƕ��ʽ���rֵ2000Ԫ��Ƕ��ʽ���b�̴̳�Y�����M�ͣ����㶮Ƕ���rֵ1000Ԫ������ARMϵ��ҕ�l������̳����r���t���������¡�ARM�n���n�Ì�䛾��A��ҕ�l���M�Iȡ���Ⱥ�ԴǶ��ʽ���r����ϵ�y��RTOS���Еr�g�|�l�c�¼��|�l�������Arm Cortex-M55��������AIָ��Uչ�c�����{�������[ʽ��ʾ��3D�������s�c���r��Ⱦ���g���`Rust�Z������CǶ��ʽ�_�l�е���ɱ������c�ȴ氲ȫ��Ԅӻ��C���W��(AutOML)��Ƕ��ʽҕ�X�΄��е�NAS���Zephyr RTOS�ڮ������̎�����е��΄շ����cؓ�d�������ڏ����W���ęC����·��Ҏ���㷨��ROS�еČ��F�c�� Ƕ��ʽLinuxϵ�y��eBPF���g���F���r�W�j�����O�������¼��ӵĮ���IO��܌��F�cЧ�ܷ����������ɿ�¡���ܣ�PUF����Ƕ��ʽ�O����������c����
�n�̷������A���hҊ��NXP�Ƴ�i.MX8M Plus�_�l�c���`�n�̷���������HarmonyOSϵ�y�����W�_�l�����n�̣��n�̷�����HaaS EDU K1�_�l�̳̣����n��ҕ�l��Դ�a���°�C�Z�Ծ���֮�����Z��ҕ�l�̳��ذ�ٛ�ͣ�Ƕ��ʽ���rֵ2000Ԫ��Ƕ��ʽ���b�̴̳�Y�����M�ͣ����㶮Ƕ���rֵ1000Ԫ������ARMϵ��ҕ�l������̳����r���t���������¡�ARM�n���n�Ì�䛾��A��ҕ�l���M�Iȡ���Ⱥ�ԴǶ��ʽ���r����ϵ�y��RTOS���Еr�g�|�l�c�¼��|�l�������Arm Cortex-M55��������AIָ��Uչ�c�����{�������[ʽ��ʾ��3D�������s�c���r��Ⱦ���g���`Rust�Z������CǶ��ʽ�_�l�е���ɱ������c�ȴ氲ȫ��Ԅӻ��C���W��(AutOML)��Ƕ��ʽҕ�X�΄��е�NAS���Zephyr RTOS�ڮ������̎�����е��΄շ����cؓ�d�������ڏ����W���ęC����·��Ҏ���㷨��ROS�еČ��F�c�� Ƕ��ʽLinuxϵ�y��eBPF���g���F���r�W�j�����O�������¼��ӵĮ���IO��܌��F�cЧ�ܷ����������ɿ�¡���ܣ�PUF����Ƕ��ʽ�O����������c����

