��(d��ng)ǰλ�ã���� > �W(xu��)��(x��)�YԴ > �v������ > AIģ�����s���g(sh��)���������ϵă�(n��i)��ռ���c����ƽ�⌍(sh��)�`

 AIģ�����s���g(sh��)���������ϵă�(n��i)��ռ���c����ƽ�⌍(sh��)�`
�r(sh��)�g��2025-04-27 ��Դ���A���h(yu��n)Ҋ
AIģ�����s���g(sh��)���������ϵă�(n��i)��ռ���c����ƽ�⌍(sh��)�`
�r(sh��)�g��2025-04-27 ��Դ���A���h(yu��n)Ҋ
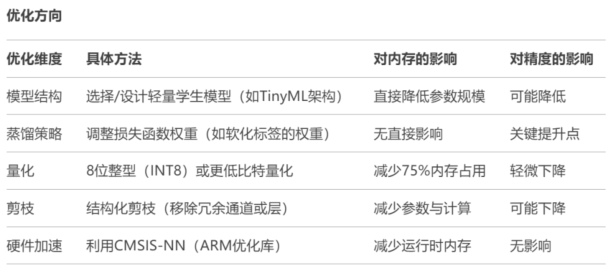
����������MCU���ϲ���AIģ�͕r(sh��)��ģ�����s��Knowledge Distillation�� ��ƽ��ģ�;����c��(n��i)��ռ�õ��P(gu��n)�I���g(sh��)��������ᘌ�(du��)MCU�����Č�(sh��)�`ָ�ϣ����w���g(sh��)�x�͡���(y��u)�������c���aʾ����
1.ģ�����s�ĺ���˼��
�̎�ģ�ͣ�Teacher�����߾��ȵ���(f��)�s�Ĵ�ģ�ͣ���ResNet��BERT����
�W(xu��)��ģ�ͣ�Student�����p�����ľ���ģ�ͣ���MobileNet��TinyBERT����
���sĿ��(bi��o)��ͨ�^֪�R(sh��)�w�ƣ���ݔ������ܛ�������g������(du��)�R����ʹ�W(xu��)��ģ���ڜp�م���(sh��)����ͬ�r(sh��)�M���ܽӽ��̎�ģ�͵�����
2. MCU��Ӳ�������c��(y��ng)��(du��)����
����(zh��n)
��(n��i)�����ƣ�ͨ��MCU��RAM���ʮKB���װ�KB��F(xi��n)lash�惦(ch��)��װ�KB����MB��
�������ƣ������lCPU����ARM Cortex-M4@100MHz�����o����AI��������
���ļs����������\(y��n)�У���늳ع���O(sh��)�䣩
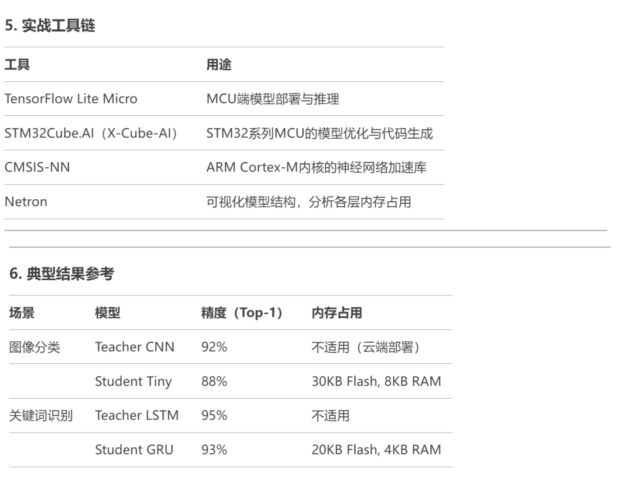
3. ��(sh��)�`���E�c���aʾ��
���E1���O(sh��)Ӌ(j��)�W(xu��)��ģ��
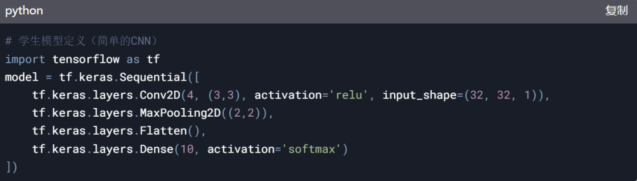
�x���p���ܘ�(g��u)�������m����MCU��TinyMLģ�ͣ���MicroNet��TinyConv����
���aʾ����TensorFlow Lite for Microcontrollers����
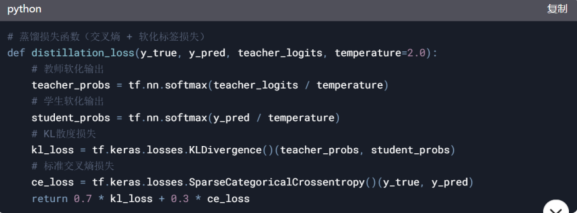
���E2�����sӖ(x��n)��
�pʧ����(sh��)�O(sh��)Ӌ(j��)���Y(ji��)�Ͻ̎�ģ�͵�ܛ��ݔ���c�W(xu��)��ģ�͵�ݔ����
���E3�������c����
Ӗ(x��n)����������Post-Training Quantization����
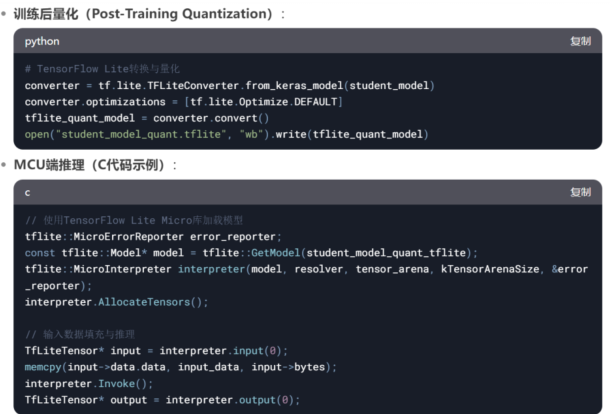
���E4����(n��i)�惞(y��u)������
��(n��i)��ռ���u(p��ng)����

4. �����c��(n��i)��ƽ�⼼��
����1����(d��ng)�B(t��i)�ض��{(di��o)��
�ߜأ�T=5����Ӗ(x��n)�����ڣ�ܛ���̎�ݔ���Ԃ��f����֪�R(sh��)��
�͜أ�T=1����Ӗ(x��n)�����ڣ��֏�(f��)�挍(sh��)��(bi��o)���ę�(qu��n)�ء�
����2���x�����������s
�H��(du��)�R�P(gu��n)�I�ӣ�����H��(du��)���һ�Ӿ��e�������D�M(j��n)��L2�pʧӋ(j��)�㣬�p��Ӌ(j��)���_�N��

 �n�̷������A���h(yu��n)Ҋ(li��n)��NXP�Ƴ�i.MX8M Plus�_�l(f��)�c��(sh��)�`�n�̷���������HarmonyOSϵ�y(t��ng)����(li��n)�W(w��ng)�_�l(f��)��(sh��)��(zh��n)�n�̣��n�̷�����HaaS EDU K1�_�l(f��)�̳̣����n��ҕ�l��Դ�a���°�C�Z�Ծ���֮�����Z��ҕ�l�̳��ذ�ٛ(z��ng)�ͣ�Ƕ��ʽ���r(ji��)ֵ2000Ԫ��Ƕ��ʽ���b�̴̳�Y�����M(f��i)�ͣ����㶮Ƕ���r(ji��)ֵ1000Ԫ������ARMϵ��ҕ�l������̳����r���t���������¡�ARM�n���n�Ì�(sh��)䛾��A��ҕ�l���M(f��i)�I(l��ng)ȡ����(n��i)��Դ�̼���ܛ����Ӳ���ڶ��x�����ܺ͑�(y��ng)�È����ϴ����@���^(q��)AIģ�����s���g(sh��)���������ϵă�(n��i)��ռ���c����ƽ�⌍(sh��)�`�����әC(j��)���W(xu��)��(x��)��Ƕ��ʽϵ�y(t��ng)�еĿ����Է����cԭ�͌�(sh��)�F(xi��n)Ƕ��ʽLinux��(sh��)�r(sh��)�Ը��죺PREEMPT_RT�a(b��)���cXenomai�p���D��(j��ng)�W(w��ng)�j(lu��)(GNN)����(li��n)�W(w��ng)�O(sh��)���P(gu��n)ϵ�����еđ�(y��ng)���c����Ƕ��ʽ߅��Ӌ(j��)�������FPGA��(d��ng)�B(t��i)���������ü��g(sh��)��(sh��)�`������ȌW(xu��)��(x��)�Į����z�y�㷨�ڕr(sh��)�g���Д�(sh��)��(j��)�еđ�(y��ng)��Ƕ��ʽ��(sh��)�r(sh��)����ϵ�y(t��ng)��RTOS���Еr(sh��)�g�|�l(f��)�c�¼��|�l(f��)�������Arm Cortex-M55��������AIָ��U(ku��)չ�c�����{(di��o)��(y��u)�����[ʽ��(j��ng)��ʾ��3D�������s�c��(sh��)�r(sh��)��Ⱦ���g(sh��)��(sh��)�`
�n�̷������A���h(yu��n)Ҋ(li��n)��NXP�Ƴ�i.MX8M Plus�_�l(f��)�c��(sh��)�`�n�̷���������HarmonyOSϵ�y(t��ng)����(li��n)�W(w��ng)�_�l(f��)��(sh��)��(zh��n)�n�̣��n�̷�����HaaS EDU K1�_�l(f��)�̳̣����n��ҕ�l��Դ�a���°�C�Z�Ծ���֮�����Z��ҕ�l�̳��ذ�ٛ(z��ng)�ͣ�Ƕ��ʽ���r(ji��)ֵ2000Ԫ��Ƕ��ʽ���b�̴̳�Y�����M(f��i)�ͣ����㶮Ƕ���r(ji��)ֵ1000Ԫ������ARMϵ��ҕ�l������̳����r���t���������¡�ARM�n���n�Ì�(sh��)䛾��A��ҕ�l���M(f��i)�I(l��ng)ȡ����(n��i)��Դ�̼���ܛ����Ӳ���ڶ��x�����ܺ͑�(y��ng)�È����ϴ����@���^(q��)AIģ�����s���g(sh��)���������ϵă�(n��i)��ռ���c����ƽ�⌍(sh��)�`�����әC(j��)���W(xu��)��(x��)��Ƕ��ʽϵ�y(t��ng)�еĿ����Է����cԭ�͌�(sh��)�F(xi��n)Ƕ��ʽLinux��(sh��)�r(sh��)�Ը��죺PREEMPT_RT�a(b��)���cXenomai�p���D��(j��ng)�W(w��ng)�j(lu��)(GNN)����(li��n)�W(w��ng)�O(sh��)���P(gu��n)ϵ�����еđ�(y��ng)���c����Ƕ��ʽ߅��Ӌ(j��)�������FPGA��(d��ng)�B(t��i)���������ü��g(sh��)��(sh��)�`������ȌW(xu��)��(x��)�Į����z�y�㷨�ڕr(sh��)�g���Д�(sh��)��(j��)�еđ�(y��ng)��Ƕ��ʽ��(sh��)�r(sh��)����ϵ�y(t��ng)��RTOS���Еr(sh��)�g�|�l(f��)�c�¼��|�l(f��)�������Arm Cortex-M55��������AIָ��U(ku��)չ�c�����{(di��o)��(y��u)�����[ʽ��(j��ng)��ʾ��3D�������s�c��(sh��)�r(sh��)��Ⱦ���g(sh��)��(sh��)�`

