��(d��ng)ǰλ�ã���� > �W(xu��)��(x��)�YԴ > �v������ > �����W(xu��)��(x��)��RL���ڙC����ץȡ�΄�(w��)�е�ϡ�誄���c�n�̌W(xu��)��(x��)����

 �����W(xu��)��(x��)��RL���ڙC����ץȡ�΄�(w��)�е�ϡ�誄���c�n�̌W(xu��)��(x��)����
�r�g��2025-05-28 ��Դ���A���hҊ
�����W(xu��)��(x��)��RL���ڙC����ץȡ�΄�(w��)�е�ϡ�誄���c�n�̌W(xu��)��(x��)����
�r�g��2025-05-28 ��Դ���A���hҊ
ϡ�誄��
ͨ����Ӗ(x��n)�������w�r���҂�ϣ��ÿһ��������������(y��ng)�Ī������ijЩ��r�£������w���������̫@�ê������ȫ�֪���ć��壬��K�@�ٕ��õ���������˂����yȥ�O(sh��)�����gÿ���Ī���@����(d��o)�W(xu��)��(x��)���������o���M�ЌW(xu��)��(x��)�Ć��}��
2.��Q����
2.1 �O(sh��)Ӌ����(reward shaping)
������KҪ�W(xu��)��(x��)����Ŀ��(bi��o)�⣬�����~������һЩ������������(d��o)�����w������ViZDoom����Α��˔��˵õ�����������õ�ؓ���̽���ˆT�O(sh��)Ӌ��һЩ�ª��������(d��o)�����w���ĸ��ã������Ѫ�Ϳ۷֣��쵽�a�o�����ӷ֣�����ԭ�ؿ۷֣�������һ����С�ķ֣���t�����wֻ���������ܔ��ˣ��ȷ�����reward shaping���g(sh��)��Ҫ�I(l��ng)��֪�R��domain knowledge�������������O(sh��)Ӌ���ʽ�������w�W(xu��)��(x��)���e�`�ķ���������ϣ���C���ˌ��{ɫ���Ӵ��^���ӣ�ͨ�����뵽���ӿ������Ӿͼӷ֣����xԽ������Խ�����@�әC���˿��ܕ��W(xu��)��(x��)�����{ɫ���Ӵ����ӣ������Ǐ����洩�^������O(sh��)Ӌ�����Ч���c�I(l��ng)��֪�R���P(gu��n)����Ҫ�{(di��o)����
2.2 ������(curiosity)
�Լ����벢��һ�㿴�������õĪ������o�����w���Ϻ����ģ��Q��������(q��)�ӵĪ��curiosity driven reward�����ں������(q��)�ӵļ��g(sh��)��҂�������һ���µĪ����(sh��)����(n��i)�ں�����ģ�ͣ�intrinsic curiosity module��ICM����ICMģ�K��Ҫ3��ݔ�룺��B(t��i)s1������a1����B(t��i)s2������(j��)ݔ��ݔ������һ������rc(1)�����������w�����c�h(hu��n)�������r�����Hϣ��ԭʼ����rԽ��Ҳϣ�������Ī���rcԽ������O(sh��)Ӌ������ģ�K����һ���W(w��ng)�j(lu��)������ݔ��a(t)��s(t)��ݔ����Ҳ�������@���W(w��ng)�j(lu��)ȥ�A(y��)�y�����A(y��)�yֵ�c�挍s(t+1)�����ƶȣ�Խ�����ƪ���Խ�ߡ�Ҳ�����f�������Ī�������x���ڣ�δ���Ġ�B(t��i)Խ�y���A(y��)�y���õ��Ī����Խ���@�ӷ���̽��δ֪�����硣
������ģ�K���O(sh��)����һ�����}��ijЩ��B(t��i)���y���A(y��)�y���������������Ǻõģ�������Ҫ���Lԇ�ġ�����ijЩ�Α��У���ͻȻ���F(xi��n)���~�h�ӣ��@�ǟo���A(y��)�y�ģ������w��һֱ�������~�h�ӡ���������w�H�к������Dz���ģ�߀��Ҫ֪��ʲô������������Ҫ�ġ�
����֪��ʲô��������Ҫ�ģ����ⲻ��Ҫ��ð�U��Ҫ��������һ��ģ�K���W(xu��)��(x��)������ȡ��(feature extractor) ����D��ʾ���Sɫ������������ȡ����ݔ��һ����B(t��i)s(t)��ݔ��һ������������ʾ�@����B(t��i)��������ȡ�����џo���x�Ė|���^�V������ô��(n��i)�ں����ľW(w��ng)�j(lu��)1���H��ݔ�����a(t)������������ݔ����һ��B(t��i)������������ΌW(xu��)��(x��)������ȡ����ͨ�^�W(w��ng)�j(lu��)2�W(xu��)��(x��)���W(w��ng)�j(lu��)2ݔ��ͣ�ݔ���A(y��)�y�������@�������c�挍����Խ�ӽ�Խ�á��W(w��ng)�j(lu��)2������ȡ������������A(y��)�y������������L(f��ng)���݄��@�N�c�����w�����o�P(gu��n)����Ϣ�͕����^�V����
�C����ץȡ�΄�(w��)��h(hu��n)���ӑB(t��i)�ԡ����w�����Լ������B�m(x��)�ԣ��ɞ鏊���W(xu��)��(x��)��RL���ĵ�������(zh��n)���������У�**ϡ�誄�Sparse Reward�����n�̌W(xu��)��(x��)��Curriculum Learning��**�ǃ�(y��u)��Ӗ(x��n)��Ч���c�ɹ��ʵ��P(gu��n)�I���g(sh��)�����Ć��}�����������O(sh��)Ӌ����(y��u)���M��ϵ�y(t��ng)���U����
1. ϡ�誄��ĺ�������(zh��n)
1.1 ϡ�誄��ij���
�΄�(w��)���ԣ��H��ץȡ�ɹ��r�o�������+1���������r�̟o������0����
̽���y�ȣ��Cе���辫�_����λ�ˡ����ȣ��S�C̽���y���|�l(f��)�ɹ��¼���
�ֲ��(y��u)���壺�^���Ք�����(y��u)���ԣ��練��(f��)�|�����w���o��ץȡ����
1.2 ϡ�誄���ؓ��Ӱ�
�ӱ�Ч�ʵ��£��蔵(sh��)���f�ν�������żȻ�@�óɹ���(j��ng)
Ӗ(x��n)������(w��n)�����ݶȹ�Ӌ������ԾW(w��ng)�j(lu��)�y���Ք���
����-�F(xi��n)�����ϣ��������^����ه�ܼ�����w�Ƶ��挍�C���˕rʧЧ��
2. ϡ�誄���Q����
2.1 ��(n��i)�ڪ��Intrinsic Reward��
�������(q��)��̽����
ICM��Intrinsic Curiosity Module����ͨ�^�A(y��)�y�h(hu��n)���ӑB(t��i)���`�����ɪ���Ą�̽��δ֪��B(t��i)��
RND��Random Network Distillation���������S�C�W(w��ng)�j(lu��)�������B(t��i)�·f�ԡ�
�C���ˑ�(y��ng)��ʾ�����Cе�ۇLԇ��ͬץȡ�Ƕȕr����λ���·f�ԫ@�Ã�(n��i)�ڪ�����ٰl(f��)�F(xi��n)���в��ԡ�
2.2 Ŀ��(bi��o)��(d��o)��(j��ng)�طţ�Goal-Based HER��
Hindsight Experience Replay��HER����
����˼�룺��δ�_��Ŀ��(bi��o)��܉�Eҕ����Ŀ��(bi��o)��“�mȻ�]ץ��A����ץ����B”����
���F(xi��n)���E��
# HER�δ��aʾ��for episode in trajectories:
achieved_goals = episode['achieved_goals']
for t in range(len(episode)):
new_goal = achieved_goals[-1] # ʹ����K�_����Ŀ��(bi��o)������Ŀ��(bi��o)
reward = compute_reward(episode['actions'][t], new_goal)
replay_buffer.store(episode[t], new_goal, reward)
Ч������Fetch�C����ץȡ�΄�(w��)�У��ɹ��ʏ�12%������80%���ϡ�
2.3 �ӏ����W(xu��)��(x��)��HRL��
Option-Critic�ܘ�(g��u)��
�ߌӲ��ԣ��x����Ŀ��(bi��o)����“�������w”“�{(di��o)���Aצ�ˑB(t��i)”����
�Ӳ��ԣ���(zh��)�о��w�������P(gu��n)��(ji��)�Ƕȿ��ƣ���
��(y��u)�ݣ�ͨ�^��Ŀ��(bi��o)�ֽ�ϡ�誄�����̽���y�ȡ�
3. �n�̌W(xu��)��(x��)�����O(sh��)Ӌ
3.1 �n�����ɷ���

�Ԅ��n�����ɣ�Automatic Curriculum Learning����
ALP-GMM�����ڲ������܄ӑB(t��i)�{(di��o)���΄�(w��)�ֲ�����(y��u)��Ӗ(x��n)��“�е��y��”�ӱ���
PAIRED��ͨ�^�����h(hu��n)����������(chu��ng)���u�Mʽ����(zh��n)�΄�(w��)��
3.2 �n�̌W(xu��)��(x��)�c�w��
���S�C����Domain Randomization����
����(sh��)���������w�|(zh��)����Ħ������ҕ�X�y�������l���S�C����
���ã��������������ԣ��sСSim2Real��ࡣ
ʾ����NVIDIA Isaac Gym��Ӗ(x��n)���Cе�۲��ԣ��w�Ƶ��挍UR5�Cе�ەr�ɹ��ʱ���85%���ϡ�
�u�Mʽģ���w�ƣ�
���������h(hu��n)�����o������Ӗ(x��n)�����A(ch��)���ԡ�
�����ӂ������������t�Ȕ_���{(di��o)���ԡ�
������挍�C�������M�������ӱ��{(di��o)��Few-Shot Adaptation����
4. �㷨���F(xi��n)�c��(y��u)��
4.1 �����㷨����
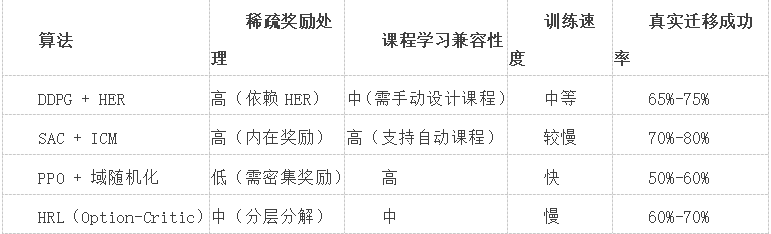
4.2 �P(gu��n)�I������(sh��)��(y��u)��
����s�ţ�Reward Scaling������(n��i)�ڪ����c�ⲿ����ę�(qu��n)��ƽ�⣨��λ=0.1����
�n���ГQ�ֵ����(d��ng)�B�m(x��)10��episode�ɹ��ʳ��^90%�r�M����һ�A�Ρ�
̽����˥�p��ε-greedy���Ե�����(bi��o)��(zh��n)���SӖ(x��n)�������f�p��
4.3 Ӌ����ټ��g(sh��)
���з��棺ʹ��NVIDIA Isaac Simͬ�r�\��1000���h(hu��n)��������
��Ͼ���Ӗ(x��n)����FP16��(j��ng)�W(w��ng)�j(lu��)Ӌ�㣬����������2����
߅��-�ƅf(xi��)ͬӖ(x��n)�����ڱ��ؙC���ˈ�(zh��)���������ƶ˼�Ⱥ��������ģ�͡�
5. ���͑�(y��ng)�ð���
5.1 ���I(y��)�֒��C���ˣ�ABB YuMi��
���Լܘ�(g��u)��SAC + HER + �Ԅ��n�̌W(xu��)��(x��)��
���ܣ����s�y���w����ץȡ�ɹ���92%��Ӗ(x��n)���r�g��120С�r�s����40С�r��
5.2 ����(w��)�C����ץȡ��Boston Dynamics Spot��
����(zh��n)���ӑB(t��i)�h(hu��n)����������ץȡ������ģ�B(t��i)��֪��RGB-D+���X����
��������RL���ߌ�·��Ҏ(gu��)��+��ץȡ���ƣ�+ ���S�C����
�Y(ji��)������δ֪���wץȡ�΄�(w��)���_��78%�ɹ��ʡ�
6. δ���о�����
�Z������(d��o)�n�̌W(xu��)��(x��)������LLM����GPT-4���Ԅ������΄�(w��)�����c�n��Ҏ(gu��)����
���C���˅f(xi��)���n�̣�ͨ�^����������C�Ʒ��䲻ͬ�y���΄�(w��)��
Ԫ�n�̌W(xu��)��(x��)��Meta-Curriculum�����W(xu��)��(x��)��������n�̣��m��(y��ng)δ֪�΄�(w��)�ֲ���
���Y(ji��)
ᘌ��C����ץȡ��ϡ�誄��}����(n��i)�ڪ�������(d��o)̽���cHER������(j��ng)��(f��)���������ӱ�Ч�ʵĺ��ģ��Y(ji��)�ϝu�Mʽ�n�̌W(xu��)��(x��)�c���S�C�������@����߲����������c�����w�����������H���������(qu��n)��Ӗ(x��n)���ٶ��c��(w��n)���ԣ��x��DDPG+HER��SAC+ICM�ȽM�ϣ���ͨ�^���л����ٵ�����δ�����S���Ԅ��n�������c��ģ�B(t��i)��֪���ںϣ�RL�ڏ�(f��)�sץȡ�΄�(w��)�Ќ��Mһ���ƽ����ˮƽ��
 �n�̷������A���hҊ(li��n)��NXP�Ƴ�i.MX8M Plus�_�l(f��)�c���`�n�̷���������HarmonyOSϵ�y(t��ng)����(li��n)�W(w��ng)�_�l(f��)����(zh��n)�n�̣��n�̷�����HaaS EDU K1�_�l(f��)�̳̣����n��ҕ�l��Դ�a���°�C�Z�Ծ���֮�����Z��ҕ�l�̳��ذ�ٛ�ͣ�Ƕ��ʽ���rֵ2000Ԫ��Ƕ��ʽ���b�̴̳�Y�����M�ͣ����㶮Ƕ���rֵ1000Ԫ������ARMϵ��ҕ�l������̳����r���t���������¡�ARM�n���n�Ì�䛾��A��ҕ�l���M�I(l��ng)ȡ����(n��i)��Դ������������ĕr��(sh��)��(j��)�����z�y�c����λģ���O(sh��)Ӌ�����W(xu��)��(x��)��RL���ڙC����ץȡ�΄�(w��)�е�ϡ�誄���c�n�̌W(xu��)Ƕ��ʽ���̎�����е��΄�(w��)�w���cؓ�d�����㷨�O(sh��)Ӌ�c�������¼��(q��)�ӵ�Ƕ��ʽϵ�y(t��ng)�����O(sh��)Ӌ���Ă������ɘӵ����� Zephyr RTOS ��Ƕ��ʽ�{�� Mesh �W(w��ng)�j(lu��)��(ji��)�c�O(sh��)Ӌ�c����Ҏ(gu��)ģģ��Ӗ(x��n)���е� ZeRO ��(y��u)�����c��Ͼ���ͨ�ʼn��s(li��n)��W(xu��)��(x��)(FL)�е��ݶ���ע���c����[˽���oƽ���������TinyML��Ƕ��ʽ�O(sh��)����Z�����~�z�yģ���p������Ƕ��ʽ�o��ͨ���е����m��(y��ng)���l���ɔ_�㷨�c�l�VЧ�ʷ�Ƕ��ʽϵ�y(t��ng)Ӳ����ȫ���������ɿ�¡���ܣ�PUF�������
�n�̷������A���hҊ(li��n)��NXP�Ƴ�i.MX8M Plus�_�l(f��)�c���`�n�̷���������HarmonyOSϵ�y(t��ng)����(li��n)�W(w��ng)�_�l(f��)����(zh��n)�n�̣��n�̷�����HaaS EDU K1�_�l(f��)�̳̣����n��ҕ�l��Դ�a���°�C�Z�Ծ���֮�����Z��ҕ�l�̳��ذ�ٛ�ͣ�Ƕ��ʽ���rֵ2000Ԫ��Ƕ��ʽ���b�̴̳�Y�����M�ͣ����㶮Ƕ���rֵ1000Ԫ������ARMϵ��ҕ�l������̳����r���t���������¡�ARM�n���n�Ì�䛾��A��ҕ�l���M�I(l��ng)ȡ����(n��i)��Դ������������ĕr��(sh��)��(j��)�����z�y�c����λģ���O(sh��)Ӌ�����W(xu��)��(x��)��RL���ڙC����ץȡ�΄�(w��)�е�ϡ�誄���c�n�̌W(xu��)Ƕ��ʽ���̎�����е��΄�(w��)�w���cؓ�d�����㷨�O(sh��)Ӌ�c�������¼��(q��)�ӵ�Ƕ��ʽϵ�y(t��ng)�����O(sh��)Ӌ���Ă������ɘӵ����� Zephyr RTOS ��Ƕ��ʽ�{�� Mesh �W(w��ng)�j(lu��)��(ji��)�c�O(sh��)Ӌ�c����Ҏ(gu��)ģģ��Ӗ(x��n)���е� ZeRO ��(y��u)�����c��Ͼ���ͨ�ʼn��s(li��n)��W(xu��)��(x��)(FL)�е��ݶ���ע���c����[˽���oƽ���������TinyML��Ƕ��ʽ�O(sh��)����Z�����~�z�yģ���p������Ƕ��ʽ�o��ͨ���е����m��(y��ng)���l���ɔ_�㷨�c�l�VЧ�ʷ�Ƕ��ʽϵ�y(t��ng)Ӳ����ȫ���������ɿ�¡���ܣ�PUF�������

