
 ���wһ����Batch Normalization������ȌW���е�����
�r�g��2025-01-09 ��Դ���A���hҊ
���wһ����Batch Normalization������ȌW���е�����
�r�g��2025-01-09 ��Դ���A���hҊ
����ȌW�����о��͑����У��W�jģ�͵�Ӗ���^�̳�����M�����S���W�j�Ӕ��ļ��Ӗ������W�j�r�������F�ݶ���ʧ���ݶȱ�ը�Ć��}������Ӗ���ٶȾ����������o���Ք������˽�Q�@һ���}�����wһ����Batch Normalization, BN�����\�����������H�܉���پW�j��Ӗ���^�̣�߀�����ģ�͵ķ����Ժͷ���������
���Č�Ԕ��̽ӑ���wһ���Ĺ���ԭ��������ȌW���е����ã��Լ����ڌ��H�����еă����c����
һ�����wһ���Ĺ���ԭ��
���wһ����BN�������Sergey Ioffe��Christian Szegedy��2015����������ĺ���˼������ÿһ�ӵ�ݔ�딵�����M�И˜ʻ���ʹ��ÿ�ӵ�ݔ�������ͬ�ķֲ��������@һ����������Ч�ؾ����W�jӖ���е�һЩ��Ҋ���}��
1.1 BN�Ļ������E
�ڂ��y���W�j�У�ÿ�ӵ�ݔ����ܕ��ܵ�ǰһ��ݔ����Ӱ푣�ʹ�Ô����ֲ��l��׃�����������ھW�j�Ӕ��^��r���@�N׃�����ܷdz����ң�����Ӗ��׃�����y�����wһ������ҪĿ����Ҏ����ÿһ�ӵ�ݔ�룬ʹ���������нyһ�ľ�ֵ�ͷ��
���w���f�����wһ�����^�̿��Է֞����ׂ����E��
1.Ӌ��ÿһ��ݔ��ľ�ֵ�ͷ���
����ݔ�딵��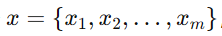 Ӌ��ԓ���Σ�batch�������ľ�ֵ�ͷ��
Ӌ��ԓ���Σ�batch�������ľ�ֵ�ͷ��
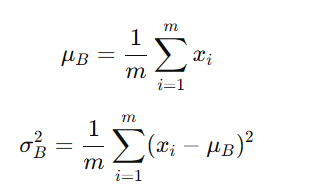
�˜ʻ�̎�����þ�ֵ�ͷ��ݔ���M�И˜ʻ���ʹ��ݔ�������ľ�ֵ��0�������1��
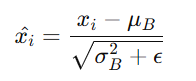
2. ����ɌW�����������˱���ģ�͵ı��_���������wһ�������˃ɂ��ɌW���ą��� γ �� β �քe���ڌ��˜ʻ��Y���M�пs�ź�ƫ�ƣ�
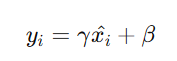
���У�γ �� β ����Ӗ���^���ЌW�����ą��������Sģ�ͻ֏͵��]�Кwһ������ʽ������������{�������ķֲ���
1.2 Ӗ���c�yԇ�A�εą^�e
��Ӗ���A�Σ�BN�ǻ��ڮ�ǰ���εľ�ֵ�ͷ����M�И˜ʻ�̎����Ȼ�����ڜyԇ�A�Σ����ڔ����������^С��ͨ���dž��ӱ������o��ʹ�î�ǰ�ӱ��ľ�ֵ�ͷ����ˣ��ڜyԇ�r��BNʹ��Ӗ���A��Ӌ�����ȫ�־�ֵ�ͷ����M�Кwһ�����Ķ��_��ģ��������r�ķ����ԡ�
�������wһ��������
���wһ������ȌW���аl�]�˶������ã���Ҫ�������ׂ����棺
2.1 ����Ӗ��
���wһ����һ���@�����c���܉��@����������W�j��Ӗ���^�̡��@����飬BNͨ�^��ÿһ�ӵ�ݔ�딵��Ҏ������ʹ������нyһ�ķֲ���������“�Ȳ��f׃��ƫ��”��Internal Covariate Shift�����ڛ]��BN����r�£��S���W�j��Ӗ����ǰ��һ�ӵę��ظ�����׃���m�ӵ�ݔ��ֲ����@�����º��m����Ҫ�����{�����أ�Ӗ���^��׃�ø��Ӿ�����������BN֮��ÿ�ӵ�ݔ��ֲ����ַ������Ķ�ʹ�þW�j�܉��Ը���ČW�����M��Ӗ�����@�������Ӗ���ٶȡ�
2.2 �����ݶ���ʧ���ݶȱ�ը
�ݶ���ʧ���ݶȱ�ը����ȾW�jӖ���г�Ҋ�ĬF������������ȾW�j���L���е���r�¡����wһ��ͨ�^����ÿ��ݔ��ľ�ֵ��0�������1����Ч�p����ݔ�딵����ƫ�ƣ�ʹ���ݶ��ڷ�������r����ƽ�����@�ӣ��W�j�������^����ݶ����M��Ӗ�����pС���ݶ���ʧ���L�U��
2.3 ���ģ�͵ķ�������
���wһ��߀������Ч�����ģ�͵ķ����������mȻBN�������~�������ÿ�����εľ�ֵ�ͷ�����������ӣ��������@�N��������һ���̶��������t�������ã��������^�M�ϡ����H�ϣ�BN������ģ�����^�ٵ����t����������Dropout������r�£�Ҳ�ܫ@���^�õķ������ܡ�
2.4 ���S���ߵČW����
�������wһ��ʹ��ÿһ�ӵ�ݔ��ֲ���������˿���ʹ���^��ČW�����M��Ӗ�����^��ČW���ʿ��Լ���ģ�͵��Ք���ͬ�r�����ˌW�����^�͌��µ�Ӗ�������Ć��}��
2.5 ���Ƴ�ʼ��
�ڛ]�����wһ���r���W�j�ą�����ʼ���Ƿdz��P�I�ģ��e�`�ij�ʼ�����܌����ݶ���ʧ��ը��Ȼ�������wһ�����Ԝp�ٌ���ʼ���������ԣ�������܉���Ч��Ҏ����ÿһ�ӵ�ݔ�룬�Ķ������˳�ʼ����Ӱ푡�
�������wһ���ľ����Ժ�����
�M�����wһ������ȌW���о����@�����ݣ�����Ҳ����һЩ�����Ժ�����
3.1 ��С������������ه
���wһ����Ҫ��ه���Δ����ľ�ֵ�ͷ����M�И˜ʻ��������̎��С���������r���yӋ�����ܲ����������������½����ژOС��������batch size=1�����ھ��W������r�£�BN��Ч��������ۿۡ�
3.2 Ӌ���_�N
���wһ���������~���Ӌ��̓ȴ��_�N���e����ÿһ�Ӷ���ҪӋ���ֵ�ͷ���r������ȾW�j�ʹ�Ҏģ�������ϣ�Ӌ��ʹ惦�@Щ�yӋ���������~���Ӌ��ɱ����M���@�N�_�Nͨ�����Ժ��Բ�Ӌ��
3.3 ��ijЩ�΄��еIJ��m����
�M�����wһ�����S���΄��б��F��ɫ������ijЩ�ض��đ��È����£������ܲ���������x�����磬��ѭ�h�W�j��RNN���У�������̎�����Д����������ԣ�BN�đ���Ч�����ܲ����ھ��e�W�j��CNN���еı��F�����˽�Q�@�����}��һЩ�о�������ˌӚwһ����Layer Normalization���ͽM�wһ����Group Normalization���ȸ��M������
3.4 ��هӖ�����ĽyӋ��
���wһ����Ӗ���r��ه��ǰ���εĔ����yӋ�������@Щ�yӋ�����ܟo����ȫ��������Ӗ�����ķֲ����@���܌�����Ӗ����׃���^��ĕr��ģ�͵����������½���
�ġ����wһ����׃�N�c�Uչ
���˿˷�BN��ijЩ�����ԣ��о��ˆT������S����M��׃�N�����������ЎN��Ҫ��׃�N��
1. �Ӛwһ����Layer Normalization�����c���wһ����ͬ���Ӛwһ���nj�ÿһ���ӱ������������M�Кwһ��̎������������һ�������M�Кwһ�����Ӛwһ��ͨ������ѭ�h�W�j��RNN���У����܉�BN��С���������ϵı��F���ѵĆ��}��
2. �M�wһ����Group Normalization�����M�wһ���nj������ֳɶ���С�M����ÿ��С�M���M�И˜ʻ����c���wһ����ͬ���M�wһ������ه�����δ�С�������С�����W����Ҳ����Ч������
3. �����wһ����Instance Normalization���������wһ��ͨ�����ڈD�������΄��У������Ɍ����W�j�������nj�ÿ���D���ÿ��ͨ���M�И˜ʻ�̎����������ȥ����ʽ��Ӱ푡�
�塢���Y
���wһ����Batch Normalization������ȌW����һ����Ҫ�ļ��g����ͨ�^Ҏ����ÿһ�ӵ�ݔ�딵����ʹ�þW�jӖ�����ӷ������������Ք��^�̣�������һ���̶��ϸ�����ģ�͵ķ����������M��������һЩ�����ԣ��猦С������������ه�Լ�Ӌ���_�N���}��������Ȼ�ǬF������W�j�в��ɻ�ȱ�ļ��g֮һ����δ�����S�����W�jӖ�����g�IJ���̽�������wһ������׃�N���ڸ������È����аl�]��������á�
 �n�̷������A���hҊ��NXP�Ƴ�i.MX8M Plus�_�l�c���`�n�̷���������HarmonyOSϵ�y�����W�_�l�����n�̣��n�̷�����HaaS EDU K1�_�l�̳̣����n��ҕ�l��Դ�a���°�C�Z�Ծ���֮�����Z��ҕ�l�̳��ذ�ٛ�ͣ�Ƕ��ʽ���rֵ2000Ԫ��Ƕ��ʽ���b�̴̳�Y�����M�ͣ����㶮Ƕ���rֵ1000Ԫ������ARMϵ��ҕ�l������̳����r���t���������¡�ARM�n���n�Ì�䛾��A��ҕ�l���M�Iȡ���Ⱥ�ԴԪ�W����Meta-Learning������Ύ���ģ�Ϳ����m���������wһ����Batch Normalization������ȌW���е�����ʲô������������̓������TCP �� UDP �ą^�e���W�jͨ�ŵăɴ��ʯ������A̎��ָ��#define��һ�����������Ա���1������ȿɷ��x���e�ھ��e�W�j�е�����׃���Ծ��a��(VAE)�c���Ɍ����W�j(GAN)�ڈD�������΄��̼���ܛ����Ӳ���ڶ��x�����ܺ͑��È����ϴ����@���^һ���x��Ӳ���r��ܛ���rarmоƬ���Linuxϵ�yʹ�õ��^��
�n�̷������A���hҊ��NXP�Ƴ�i.MX8M Plus�_�l�c���`�n�̷���������HarmonyOSϵ�y�����W�_�l�����n�̣��n�̷�����HaaS EDU K1�_�l�̳̣����n��ҕ�l��Դ�a���°�C�Z�Ծ���֮�����Z��ҕ�l�̳��ذ�ٛ�ͣ�Ƕ��ʽ���rֵ2000Ԫ��Ƕ��ʽ���b�̴̳�Y�����M�ͣ����㶮Ƕ���rֵ1000Ԫ������ARMϵ��ҕ�l������̳����r���t���������¡�ARM�n���n�Ì�䛾��A��ҕ�l���M�Iȡ���Ⱥ�ԴԪ�W����Meta-Learning������Ύ���ģ�Ϳ����m���������wһ����Batch Normalization������ȌW���е�����ʲô������������̓������TCP �� UDP �ą^�e���W�jͨ�ŵăɴ��ʯ������A̎��ָ��#define��һ�����������Ա���1������ȿɷ��x���e�ھ��e�W�j�е�����׃���Ծ��a��(VAE)�c���Ɍ����W�j(GAN)�ڈD�������΄��̼���ܛ����Ӳ���ڶ��x�����ܺ͑��È����ϴ����@���^һ���x��Ӳ���r��ܛ���rarmоƬ���Linuxϵ�yʹ�õ��^��

