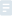Python �W�j���x
�r�g��2017-11-03 ��Դ��δ֪
Python �W�j���x
�r�g��2017-11-03 ��Դ��δ֪
���҂����Iһ���֙C�����҂���֪�������ˌ�һ��aƷ���u�r�����҂��и��N�����Ɇ��ĕr���҂�����Ҫ���_�ٶȣ�Google���������棬�������P���}�����������Լ���X����ߵ������Ϸ������ҡ��@���������Ĕ�����Դ�ڻ��W�����ٶȺ�Google����һ���Ļ��W��ץȡ�����Ĵ����x��
���҂��ڞg�[����ݔ��Wַ�l��Ո��g�[������web�������l��httpՈ��web�������ؑ��ľ����҂�Ո���html�W퓣��g�[���ٽ���html�W퓣��@ʾ���е��ı��͈DƬ����Ϣ��
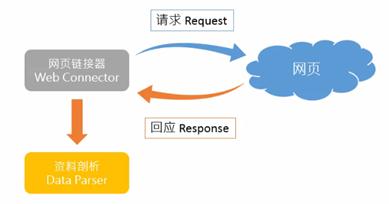
���^�ľW�j���x��������@���^�̣���ģ�M�ľ��Ǟg�[��Ո��W퓵��^�̡��@���҂�ʹ��urllib���Ԍ��Fԓ���ܡ�Ҫע��urllib��python2���Ѓɂ��汾��urllib��urllib2����python3�������ѽ������ϵ�һ�𣬽�urllib��
���´��a�@ȡ���°ٿƵľW퓣�
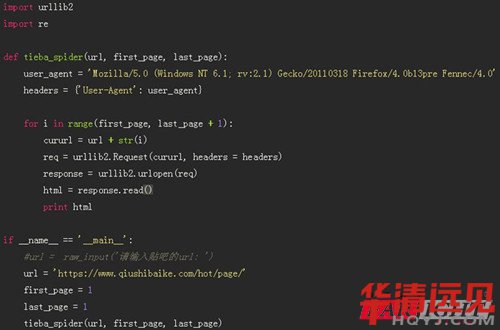
�˴��a�@ȡ����ȫ��html�W퓣��g�[�����Խ����@ʾ�����x����Ϣ���҂�����Ҫ�M��̎������ȡ��Ϣ��
�҂��l�Fhtml�W��еĶ��ӿ��ǰ������@�ӵ�html���a�У�

�҂�����ʹ�����t���_ʽ�@ȡ���еĔ��������Ӵ��a���£�
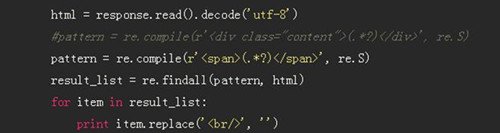
��һ��ݔ���ѽ����҂���Ҫ�@ȡ�IJ��֣�