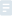��ʲô��Ҫͬ����
�r�g��2018-09-26 ��Դ��δ֪
��ʲô��Ҫͬ����
�r�g��2018-09-26 ��Դ��δ֪
1. ��ʲô��Ҫͬ����
����ĈD�Ǐġ������̡��нصĈD���mȻ����ᘌ����̵ģ������@��Ҫ�f�������H�H����Ҫ���]�@�����}��ֻҪ�漰�����l�ij���Ҫ���]ͬ����������M�̹���ȴ棬����ij���ӕ�ͬ�r�����_�����ҕ����ׂ��M��ͬ�r�����е�ֵ���Ĵ���......
ԭ���϶���һ�ӵģ��ྀ�̲��l�L����һ��Ҫע��ģ����ͬһ�M�̵Ķ������̱��������M���YԴ�����f׃���ăȴ档�����ψD���f���҂���i׃����ֵ+1��������ô�@�������Άε�+1������������CPU�ϕ���ô������?ͨ���֞�3����
(1) �ăȴ��Ԫ�x��Ĵ���
(2) �ڼĴ������M��׃��ֵ����
(3) ���µ�ֵ���ȴ��Ԫ
�@�͌������ψD�Ć��}��A�����ڰ�i�ăȴ��x��Ĵ�����׃�^����(߀�]���ص��ȴ�)��B����Ҳ��i����ͬ�Ӳ����������ں�Y�������x��Ķ���5������Ķ���6����ô�����҂���Ҫ��i����2�εģ����H�s������1�Ρ��@�N�����r�g���}���ܰl����ns���e�������Ԯ���̎�������m��GHZ���ٶȁ��f���l���@�N��r����߀�Ǻܴ�ġ�
2.��Cԇ�
�����҂��������팍�H�����@�N��r��
���³���
1. #include
2. #include
3. #include
4. #include
5.
6. #define NUM 40000000
7.
8. pthread_t tid1;
9. pthread_t tid2;
10.
11. unsigned int count1 = 0;
12. unsigned int count2 = 0;
13. unsigned int count = 0;
14.
15. void * thr_fn1(void *arg)
16. {
17. while(count1
18. {
19. count++;
20. count1++;
21. }
22. }
23.
24. void * thr_fn2(void *arg)
25. {
26. while(count2
27. {
28. count++;
29. count2++;
30. }
31. }
32.
33. int main(void)
34. {
35. int err;
36.
37. err = pthread_create(&tid1, NULL, thr_fn1, NULL);
38. if (err != 0)
39. perror("can't create thread1");
40.
41. err = pthread_create(&tid2, NULL, thr_fn2, NULL);
42. if (err != 0)
43. perror("can't create thread2");
44.
45. pthread_join(tid1, NULL);
46. pthread_join(tid2, NULL);
47.
48. printf("count = %u, count1 = %u, count2 = %u\n", count, count1, count2);
49. exit(0);
50. }
����ܺ��Σ����DŽ����ɂ����̣�Ȼ��ÿ�����̷քe��count����40000000 ֵ���@��ֵ�����S���x�ģ�ֻҪ��һ�c���У����DŽe����2^32����count1��count2�քe��ӛ䛃ɂ����̌�count�քe�����˶��ٴΣ��䌍��NUM���ƾͺ��ˣ����^���ˌ��ȣ��҂������@�ɂ�׃�������M�̄����ɂ����̺��҂���pthread_join�������ȴ��ɂ����̈����ꮅ������ӡ����ֵ���^�ó��Y����
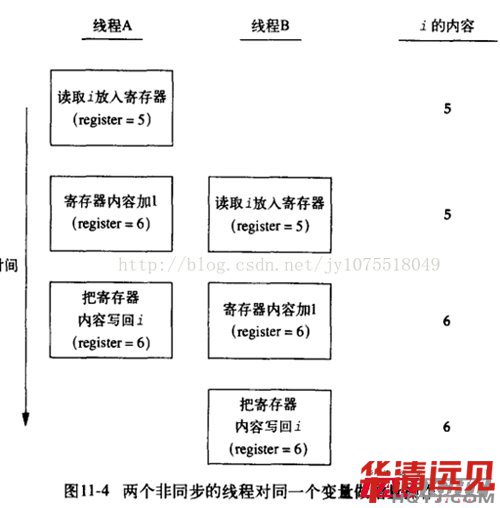
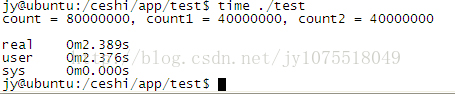
������PC�C�Ͽ��½Y����CPU���p��2.6GHZ�ģ��\�Эh����ubuntu��혱���time����鿴���Еr�g��
���ψD���Կ������ɂ����̌�count�M�п���80000000���ۼӴ����Ҫ2ms��һ�c���y��6����2�����І��}�ģ���count != count1 + count2������߀�DZ��^��ġ�
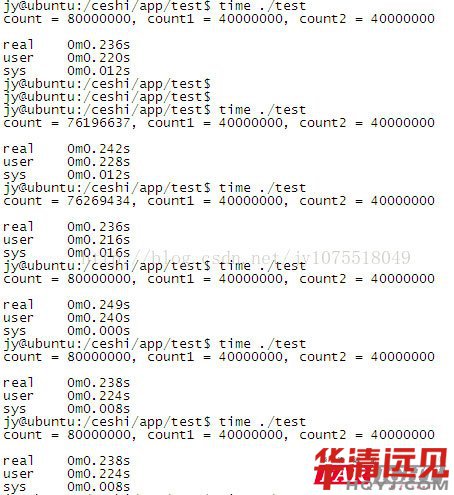
Ȼ���Ұ���ͬ�Ĵ��a���¾��g�õ�AM335x(TI A8�κ�600MHZ)�\�У��Y������
�@���r�g����ĕr�����@�L�ˣ���Ҫ���4s���������Ԟ�κ�̎�������e���ʕ�С���]�뵽�\��5�νY����Ȼȫ���e�ġ����w��ʲô���@�ӛ]ȥ������둪ԓ��SMP�C�Ƽ�����ϵ�y�����{�����P���@���Y�����C���˾���ͬ������Ҫ�ԣ���������Ƕ��ʽϵ�y�С�
3.ͬ�����}��Q����
��Ȼ���}�������ˣ�������Ȼ�ǽ�Q�����ˣ���Q�@�Nͬ�����}����ķ��������i�ˣ����Ŵ���ƽ�r�����^����linux���̎��ṩ�Ľӿڣ����a�Ğ�������ʽ��
1. #define NUM 40000000
2. pthread_mutex_t lock = PTHREAD_MUTEX_INITIALIZER;
3.
4. pthread_t tid1;
5. pthread_t tid2;
6.
7. unsigned int count1 = 0;
8. unsigned int count2 = 0;
9. unsigned int count = 0;
10.
11. void * thr_fn1(void *arg)
12. {
13. while(count1
14. {
15. pthread_mutex_lock(&lock);
16. count++;
17. pthread_mutex_unlock(&lock);
18.
19. count1++;
20. }
21. }
22.
23. void * thr_fn2(void *arg)
24. {
25. while(count2
26. {
27. pthread_mutex_lock(&lock);
28. count++;
29. pthread_mutex_unlock(&lock);
30.
31. count2++;
32. }
33. }
ֻ�г��˲��ִ��a�������Ķ�һ�ӣ��䌍˼��ܺ��Σ������ڲ��l�L��ͬһ��׃���r�o�@������׃�����i�����C��������ԭ���Լ��ɡ���ô��ʲôcount1��count2���ü��i�أ����ɂ�׃��������ֻ�ڃɂ������зքe���������ԛ]��Ҫ���i��
������½Y�������}�����ѽ���Q�ˣ������@�����c���ڽY���ϣ����ڳ�����Еr�g�ϡ��@����PC�ϽY����
�@����ARM�ϵĽY����

�����@��������PC��ͬһ�����\�Еr�g����10���������϶���6�������Լ��i�����ڱ��C�˲��l�L�����_��ͬ�r����������˳����\�Еr�g�������҂��ڶ��M�̹����YԴ���l�L�������OӋ�r����Ҫ�C�Ͽ��]��������_�Ժ�Ч�ʡ�