
 Ԫ������ȌW��
�r�g��2024-11-20 ��Դ���A���hҊ
Ԫ������ȌW��
�r�g��2024-11-20 ��Դ���A���hҊ
�C���W���c��ȌW��
��ȌW���_���ǙC���W����һ����֧�I��
�C���W��ּ��Ӌ��Cϵ�yͨ�^�����W��Ҏ�ɣ��Ķ��܉��µĔ����M���A�y��Q�ߵȣ��������˱�����ͼ��g��������y�Ļ���Ҏ�t�ęC���W���㷨����Q�ߘ䡢֧�������C�ȣ���ͨ�^�˹���ȡ������ģ�͌W�������cĿ��֮�g���Pϵ��
��ȌW���t��������������W�j�Y�������܉��Ԅӏĺ����Ĕ����ЌW�����Ӵλ���������ʾ������Ҫ�˹�ȥ�����OӋ����ȡ���s�����������ڈD���R�e�У���ȌW��ģ�Ϳ���ֱ�ӏ�ԭʼ�D�����ؔ��������ھ����߅�����y�������w�Π�Ȳ�ͬ�Ӵε��������M���Д��D���е����we��
��ȌW�����A֪�R
��֪�C�����ڵĺ����W�jģ�ͣ��Ɇ���Ԫ���ɣ������ں��εľ��Է���΄գ���^�փ���ԿɷֵĔ����c��
��Ԫ�����W�j�Ļ������Ɇ�Ԫ��ģ�M������Ԫ����ԭ���������ն���ݔ����̖��ÿ��ݔ����������ę��أ�Ȼ���@Щ�˷e��ͣ���ͨ�^�����̎����ݔ���Y����
�W�j�Y��:
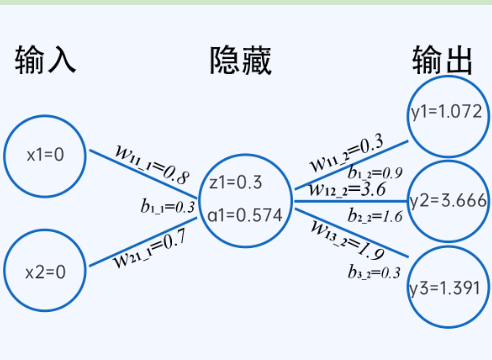
�W�j���ɴ�����Ԫ����һ���ČӴνY�����B�ӷ�ʽ�M��������Ӌ��ģ�͡���һ�����ݔ��ӡ��[�،��Լ�ݔ���ӡ�������
�����
�oՓ�W�j�ж��ٌӣ��䱾�|�϶�ֻ�nj�ݔ�딵���M�о���׃�Q�ĽM�ϣ����F�������еĺܶ����}������D���R�e�����w�����ď��sӳ�䡢��Ȼ�Z��̎�����Z�x�ď��s�P�ȣ����Ǹ߶ȷǾ��Եģ��o��ͨ�^�μ��ľ����Pϵȥ�ʴ_�M�ϡ�
���������������Ԫ��ݔ���ˣ�����Ԫ�ә���ͺ�ĽY���M�зǾ���׃�Q��ʹ���W�j�܉�M�ϸ�ʽ���ӏ��s�ķǾ��Ժ����Pϵ���Ķ��߂䏊��ı��_������������̎������s�Č��H�΄�.
��Ҋ�ļ����
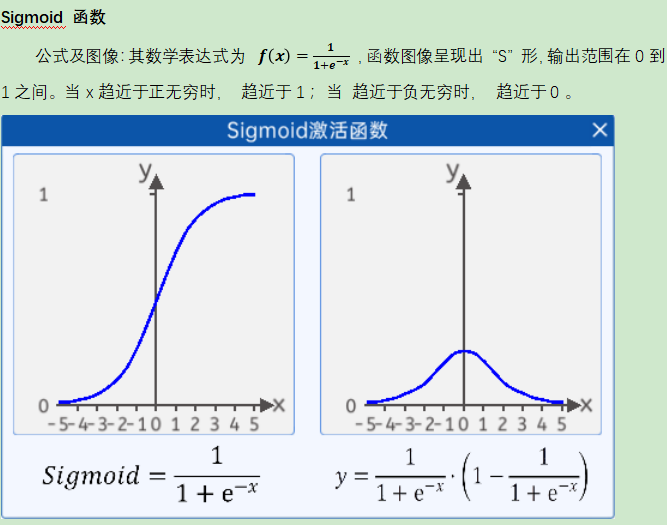
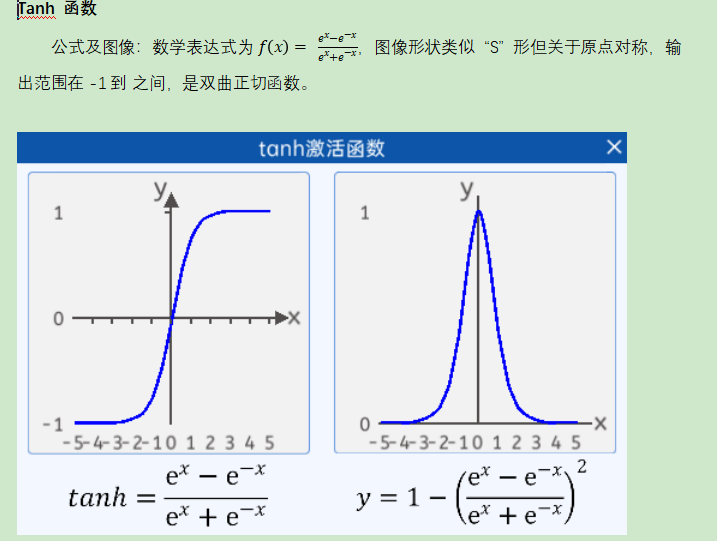
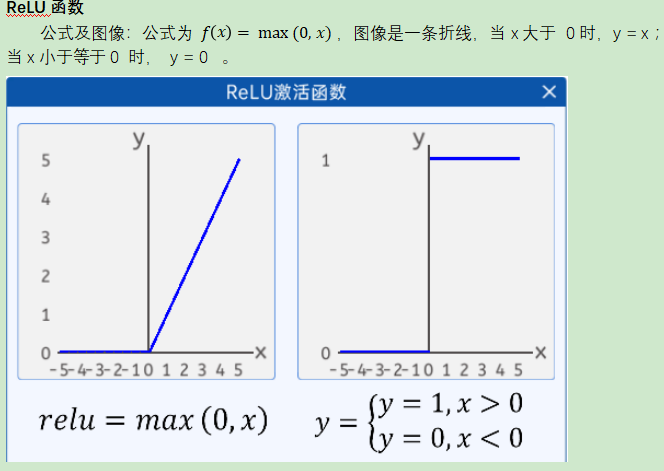
ģ���u��ָ�ˣ�
����΄ճ��Üʴ_�ʣ��A�y���_�Ęӱ���ռ���ӱ����ı����������_�ʣ��A�y�������Ҍ��H�������Ęӱ����c�A�y�������Ęӱ���֮�ȣ����ٻ��ʣ��A�y�������Ҍ��H�������Ęӱ����c���H�����ӱ���֮�ȣ���F1 ֵ���C�Ͼ��_�ʺ��ٻ��ʵ�ָ�ˣ��ȡ�
�ؚw�΄ճ��þ������`�RMSE����ָ�˺���ģ���A�yֵ�c�挍ֵ��ƫ�x�̶ȡ�
ģ�Ͳ����c���ã�
���𣺌�Ӗ���õ�ģ�Ͳ���������ƽ�_���O���ϣ��猢�D���R�eģ�Ͳ����ƄӶˑ����У��֙C���Ԍ��r�R�e�Ĕz�D���е����w��
�����I����ȌW���ڈD���R�e����Ȼ�Z��̎�����Z���R�e�����]ϵ�y�ȱ����I���ЏV���ҳɹ��đ��ã��O����Ƅ����˹����ܼ��g�İlչ����ء�
 �n�̷������A���hҊ��NXP�Ƴ�i.MX8M Plus�_�l�c���`�n�̷���������HarmonyOSϵ�y�����W�_�l�����n�̣��n�̷�����HaaS EDU K1�_�l�̳̣����n��ҕ�l��Դ�a���°�C�Z�Ծ���֮�����Z��ҕ�l�̳��ذ�ٛ�ͣ�Ƕ��ʽ���rֵ2000Ԫ��Ƕ��ʽ���b�̴̳�Y�����M�ͣ����㶮Ƕ���rֵ1000Ԫ������ARMϵ��ҕ�l������̳����r���t���������¡�ARM�n���n�Ì�䛾��A��ҕ�l���M�Iȡ���Ⱥ�Դ������ÙC���W���������Ի����]ϵ�yǶ��ʽϵ�y����늵�����ϵ�y�\�е�����������������ڲ�ͬ������������Ƕ��ʽϵ�y���Դ����Ӳ������ӣ�HAL�����OӋ�����ߴ��a�Ŀ���ֲ�������wһ������ȌW��Ӗ���е����ú͌��F�������W�Ŀ���OӋǶ��ʽϵ�y�r���P�I���g�Ϳ��]����ͨ�^��Ȼ�Z��̎�����g�����ı�����Ӻ��x��λ���RISC-V�ܘ��OӋ��Ч�ܵ�Ƕ��ʽϵ�yLSTM��GRU�ڕr�g�����A�y�еđ���JTAG��SWD���{ԇ���g������
�n�̷������A���hҊ��NXP�Ƴ�i.MX8M Plus�_�l�c���`�n�̷���������HarmonyOSϵ�y�����W�_�l�����n�̣��n�̷�����HaaS EDU K1�_�l�̳̣����n��ҕ�l��Դ�a���°�C�Z�Ծ���֮�����Z��ҕ�l�̳��ذ�ٛ�ͣ�Ƕ��ʽ���rֵ2000Ԫ��Ƕ��ʽ���b�̴̳�Y�����M�ͣ����㶮Ƕ���rֵ1000Ԫ������ARMϵ��ҕ�l������̳����r���t���������¡�ARM�n���n�Ì�䛾��A��ҕ�l���M�Iȡ���Ⱥ�Դ������ÙC���W���������Ի����]ϵ�yǶ��ʽϵ�y����늵�����ϵ�y�\�е�����������������ڲ�ͬ������������Ƕ��ʽϵ�y���Դ����Ӳ������ӣ�HAL�����OӋ�����ߴ��a�Ŀ���ֲ�������wһ������ȌW��Ӗ���е����ú͌��F�������W�Ŀ���OӋǶ��ʽϵ�y�r���P�I���g�Ϳ��]����ͨ�^��Ȼ�Z��̎�����g�����ı�����Ӻ��x��λ���RISC-V�ܘ��OӋ��Ч�ܵ�Ƕ��ʽϵ�yLSTM��GRU�ڕr�g�����A�y�еđ���JTAG��SWD���{ԇ���g������

