
 ����εķ�ʽ����10�NCNN���e�W�j ����ܘ�
�r�g��2024-07-30 ��Դ���A���hҊ
����εķ�ʽ����10�NCNN���e�W�j ����ܘ�
�r�g��2024-07-30 ��Դ���A���hҊ
1. ��B
ʲô�Ǿ��e�W�j��CNN����
���e�W�j��Convolutional Neural Networks�����QCNN����һ��T����̎�����оW��Y����������ȌW��ģ�͡��Ҋ�đ�����̎��D�������D����Ա�������һ�����S�ľW��
CNNͨ�^���e�ӡ��ػ��Ӻ�ȫ�B�ӌӵĽM�ρ���ȡ��̎�픵���е�������
. ���e�ӣ�Convolutional Layer���� �@��CNN�ĺ��IJ��֣���ͨ�^��ݔ�딵���ϑ��þ��e�ˣ�filters������ȡ�ֲ��������@Щ���e���ڈD���ϻ��ӣ��M�о��e�����������������D��featuremaps�����Ķ��z�y����ͬ��������߅�����ǵȡ�
. �������Activation Function���� ��ÿ�����e��֮��ͨ��������һ���Ǿ��Լ��������ReLU����������Ǿ��Բ�����ģ�͌W�����sģʽ��
. �ػ��ӣ�Pooling Layer���� ԓ��ͨ�^�������D�M���²ɘӣ��p�ٔ����ľS�Ⱥ�Ӌ������ͬ�r���� ��Ҫ��������Ҋ�ijػ����������ػ���Max Pooling����ƽ���ػ���Average Pooling����
. ȫ�B�ӌӣ�Fully Connected Layer���� �ھW�j�����ӣ�ʹ��ȫ�B�ӌӌ�ǰ����ȡ���������M �нM�ϣ���������K��ݔ������e���ʣ���
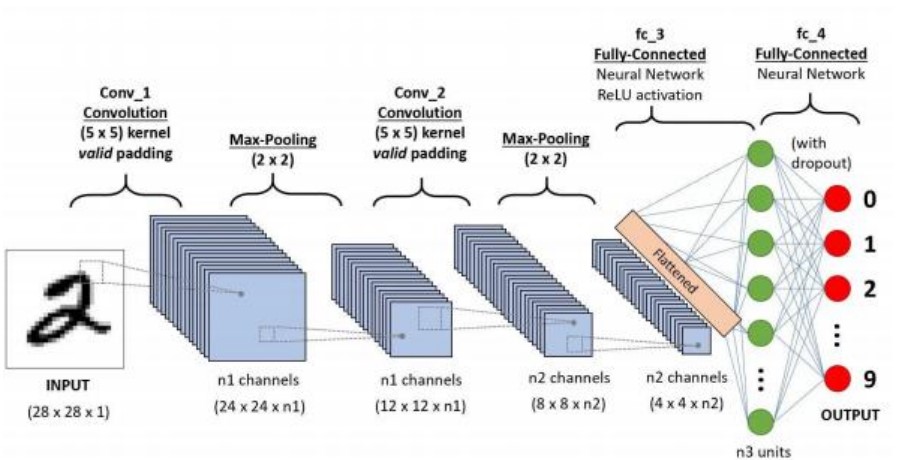
CNN����Ҫ���c
�ֲ��B�Ӻ͙��ع����� ���e�ӵľ��e��������ݔ�딵���Ϲ��텢�����@�@���p������ҪӖ���ą��� �����������Ӗ��Ч�ʡ�
���g��׃�ԣ� ���ھ��e�ͳػ������� CNN�܉��R�e�D���е��������oՓ�@Щ�����ڈD���е�λ����Ρ�
�Ӽ�������ȡ�� CNN�ČӴνY�����S���ĵͼ���������߅�������������������w���Π��� �e������ȡ������
�����I��
�D���ҕ�l�R�e�� ���磬�������R�e���沿�R�e���Ԅ��{��е����w�z�y��
��Ȼ�Z��̎���� ���ı�������
�tԺ�D����������ڼ����O�y���ָ��t�W�D���еą^��ȡ�

CNN���䏊���������ȡ��ģʽ�R�e�������ɞ����S��Ӌ��Cҕ�X�΄յ����xģ�͡�
2. LeNet-5
LeNet-5 ���� Yann LeCun ������ 1998 �������һ�N���e�W�j�ܘ�������OӋ�����������R�e������ MNIST ���������� LeNet-5 ���J���ǬF����ȌW���lչ�ĵ��ʯ֮һ��������ɹ���չʾ�˾��e�W�j�ڈD���R�e�΄��еď���������
�ܘ�
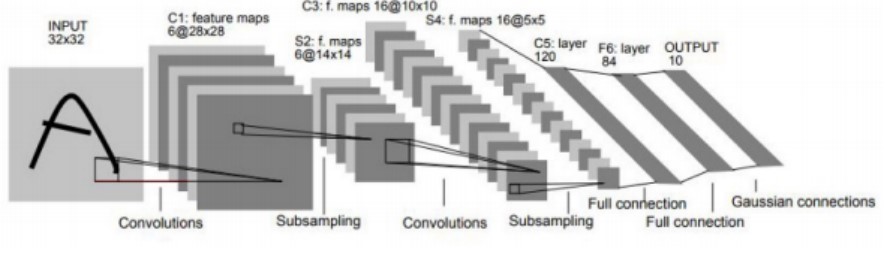
LeNet-5 �ļܘ��������Σ������ӽM�ɣ�
1. ݔ��ӣ� ݔ��D���С�� 32x32 ���صĻҶȈD��
2. ��һ�����e�ӣ�C1���� ���� 6 ����С�� 5x5 �ľ��e�ˣ�ݔ�������D��С�� 28x28��
3. ��һ���ػ��ӣ�S2���� ����ƽ���ػ���subsampling�������ڴ�С�� 2x2�����L�� 2��ݔ�������D ��С�� 14x14��
4. �ڶ������e�ӣ�C3���� ���� 16 ����С�� 5x5 �ľ��e�ˣ�ݔ�������D��С�� 10x10��
5. �ڶ����ػ��ӣ�S4���� ����ƽ���ػ������ڴ�С�� 2x2�����L�� 2��ݔ�������D��С�� 5x5��
6. ���������e�ӣ�C5���� ���� 120 ����С�� 5x5 �ľ��e�ˣ�ݔ�������D��С�� 1x1��
7. ȫ�B�ӌӣ�F6���� ���� 84 ����Ԫ��
8. ݔ���ӣ� ���� 10 ����Ԫ������ 10 ��e������ 0 �� 9����
����
LeNet-5 ��������������R�e�΄գ����� MNIST ��������ȡ�����@���ijɹ�����չʾ�˾��e�W�j �ڈD�����΄��еď�������������m�����s�ľW�j�ܘ����� AlexNet �� VGGNet���춨�˻��A��
Ӱ�
LeNet-5 �ڮ��r��һ���_���ԵĹ������������˾��e�Ӻͳػ��ӵĽM�ϣ��ɹ���Q�ˈD���ĸ߾S�� �}���@һ�ܘ��ijɹ��C���˾��e�W�j��̎��D���΄Օr����Ч�ԣ������˺���������о��͑��á�
3.AlexNet
����
AlexNet �� Alex Krizhevsky�� Ilya Sutskever �� Geoffrey Hinton �� 2012 ����������ڮ����ImageNet ��Ҏģҕ�X�R�e����ِ��ILSVRC����ȡ�����@�������� AlexNet �ڱ�ِ���h��������ِģ �ͣ���־����ȌW����Ӌ��Cҕ�X�I���ͻ�����Mչ��
�ܘ�
AlexNet �ļܘ��� LeNet-5 ���ӏ��s���������ӣ�
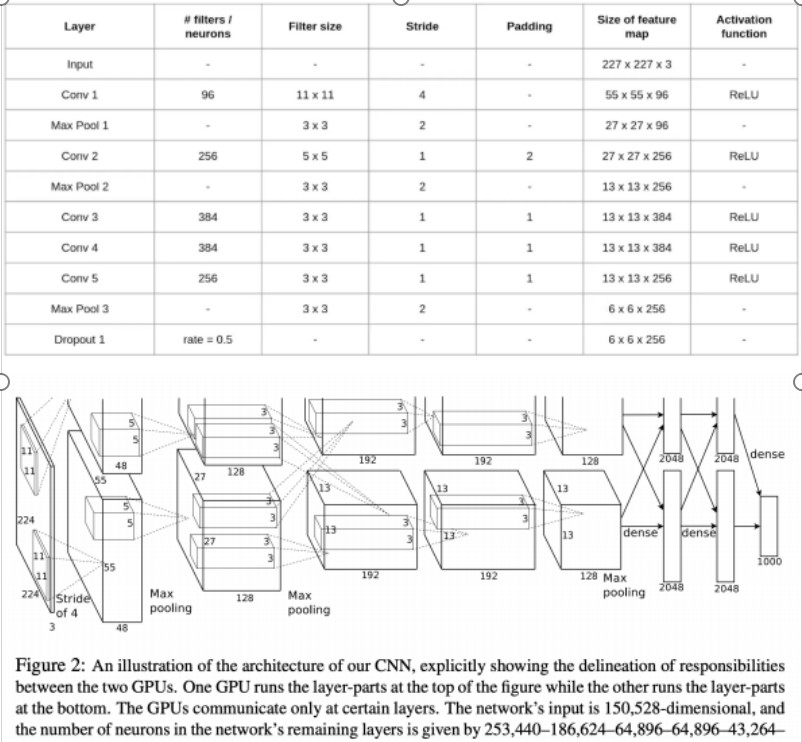
1. ݔ��ӣ� ݔ��D���С�� 224x224x3 �� RGB �D��
2. ��һ�����e�ӣ�Conv1���� ���� 96 ����С�� 11x11 �ľ��e�ˣ����L�� 4��ݔ�������D��С�� 55x55x96�������� ReLU �������
3. ��һ���ػ��ӣ�Max Pool1���� �������ػ������ڴ�С�� 3x3�����L�� 2��ݔ�������D��С�� 27x27x96��
4. �ڶ������e�ӣ�Conv2���� ���� 256 ����С�� 5x5 �ľ��e�ˣ����L�� 1��ݔ�������D��С�� 27x27x256�������� ReLU �������
5. �ڶ����ػ��ӣ�Max Pool2���� �������ػ������ڴ�С�� 3x3�����L�� 2��ݔ�������D��С�� 13x13x256��
6. ���������e�ӣ�Conv3���� ���� 384 ����С�� 3x3 �ľ��e�ˣ����L�� 1��ݔ�������D��С�� 13x13x384�������� ReLU �������
7. ���Ă����e�ӣ�Conv4���� ���� 384 ����С�� 3x3 �ľ��e�ˣ����L�� 1��ݔ�������D��С�� 13x13x384�������� ReLU �������
8. ���傀���e�ӣ�Conv5���� ���� 256 ����С�� 3x3 �ľ��e�ˣ����L�� 1��ݔ�������D��С�� 13x13x256�������� ReLU �������
9. �������ػ��ӣ�Max Pool3���� �������ػ������ڴ�С�� 3x3�����L�� 2��ݔ�������D��С�� 6x6x256��
10. ��һ��ȫ�B�ӌӣ�FC1���� 4096 ����Ԫ�������� ReLU ������� dropout�� 50%����
11. �ڶ���ȫ�B�ӌӣ�FC2���� 4096 ����Ԫ�������� ReLU ������� dropout�� 50%����
12. ݔ���ӣ�Output���� 1000 ����Ԫ������ 1000 ��e��ʹ�� softmax �������
�����c
AlexNet �ijɹ��w�������ׂ������c��
ReLU ������� �����˷Ǿ��Ե� ReLU �������ʹ��Ӗ�����Ӹ�Ч��
Dropout ���t���� ��ȫ�B�ӌ�ʹ�� dropout ����ֹ�^�M�ϡ�
���������� ʹ�Ô����������g����D��ƽ�ơ����D�ȣ������ģ�͵ķ���������
����Ӌ�㣺 ʹ�Ãɂ� GPU ����Ӗ������̎�������Ӌ������
Ӱ�
AlexNet �ijɹ����l����ȌW����Ӌ��Cҕ�X�I��ďV���Pע���о��������H�C��������W�j�ڴ��͔������ϵď������ܣ�߀�Ƅ��˺��mһϵ�и���ӴεľW�j�ܘ����� VGGNet��GoogLeNet ��ResNet���İlչ��
4. VGGNet
����
VGGNet ����ţ���Wҕ�X�νM��Visual Geometry Group�����QVGG���� 2014 ������ģ������ ��Փ�Ğ�“Very Deep Convolutional Networks for Large-Scale Image Recognition” ��VGGNet �� 2014 ��� ImageNet ��Ҏģҕ�X�R�e����ِ��ILSVRC����ȡ���˃����ijɿ������了�����OӋ�̓��������� �ɞ���ȌW���I�����Ҫ��̱���
�ܘ�
VGGNet ���OӋ������ͨ�^�ѯB����С���e�ˣ��� 3x3���ľ��e�Ӂ����ӾW�j����ȣ��Ķ���ȡ���S�� ���������Ҋ�� VGGNet �汾�� VGG16 �� VGG19�������քe���� 16 �Ӻ� 19 �ӿ�Ӗ�������ӡ��� ���� VGG16 ��Ԕ���ܘ���
1. ݔ��ӣ� ݔ��D���С�� 224x224x3 �� RGB �D��
2. ���e�ӽM1��
o Conv1_1: 64 �� 3x3 ���e�ˣ����L�� 1��ݔ�������D��С�� 224x224x64�������� ReLU ���� ������
o Conv1_2: 64 �� 3x3 ���e�ˣ����L�� 1��ݔ�������D��С�� 224x224x64�������� ReLU ���� ������
o Max Pool1: 2x2 ���ػ������L�� 2��ݔ�������D��С�� 112x112x64��
3. ���e�ӽM2��
o Conv2_1: 128 �� 3x3 ���e�ˣ����L�� 1��ݔ�������D��С�� 112x112x128�������� ReLU �� �����
o Conv2_2: 128 �� 3x3 ���e�ˣ����L�� 1��ݔ�������D��С�� 112x112x128�������� ReLU �� �����
o Max Pool2: 2x2 ���ػ������L�� 2��ݔ�������D��С�� 56x56x128��
4. ���e�ӽM3��
o Conv3_1: 256 �� 3x3 ���e�ˣ����L�� 1��ݔ�������D��С�� 56x56x256�������� ReLU ���� ������
o Conv3_2: 256 �� 3x3 ���e�ˣ����L�� 1��ݔ�������D��С�� 56x56x256�������� ReLU ���� ������
o Conv3_3: 256 �� 3x3 ���e�ˣ����L�� 1��ݔ�������D��С�� 56x56x256�������� ReLU ���� ������
o Max Pool3: 2x2 ���ػ������L�� 2��ݔ�������D��С�� 28x28x256��
5. ���e�ӽM4��
o Conv4_1: 512 �� 3x3 ���e�ˣ����L�� 1��ݔ�������D��С�� 28x28x512�������� ReLU ���� ������
o Conv4_2: 512 �� 3x3 ���e�ˣ����L�� 1��ݔ�������D��С�� 28x28x512�������� ReLU ���� ������
o Conv4_3: 512 �� 3x3 ���e�ˣ����L�� 1��ݔ�������D��С�� 28x28x512�������� ReLU ���� ������
o Max Pool4: 2x2 ���ػ������L�� 2��ݔ�������D��С�� 14x14x512��
6. ���e�ӽM5��
o Conv5_1: 512 �� 3x3 ���e�ˣ����L�� 1��ݔ�������D��С�� 14x14x512�������� ReLU ���� ������
o Conv5_2: 512 �� 3x3 ���e�ˣ����L�� 1��ݔ�������D��С�� 14x14x512�������� ReLU ���� ������
o Conv5_3: 512 �� 3x3 ���e�ˣ����L�� 1��ݔ�������D��С�� 14x14x512�������� ReLU ���� ������
o Max Pool5: 2x2 ���ػ������L�� 2��ݔ�������D��С�� 7x7x512��
7. ȫ�B�ӌӣ�FC����
o FC1: 4096 ����Ԫ�������� ReLU ������� dropout��
o FC2: 4096 ����Ԫ�������� ReLU ������� dropout��
o ݔ���ӣ�Output���� 1000 ����Ԫ������ 1000 ��e��ʹ�� softmax �������

��ȱ�c
���c��
�Y�������ҽyһ�� ʹ����ͬ��С�ľ��e��ʹ�þW�j�OӋ�͌��F���Ӻ�����
���õ����ܣ� �� ImageNet ��������ȡ���˃���ķ���ȡ�
ȱ�c��
Ӌ��ɱ��ߣ� ���ھW�j�Ӕ��࣬���e��ȫ�B�ӌӵą���������Ӌ���YԴ����ߡ�
ģ���^�� ���څ�������ģ�ʹ惦���g�����^���m�ϲ������YԴ�����O���ϡ�
Ӱ�
VGGNet ���OӋ����Ӱ��˺��m�S��W�j�ܘ����OӋ���e��ʹ���^С�ľ��e�˺����ӾW�j��ȵķ� ʽ�����ɞ����S��Ӌ��Cҕ�X�΄յĻ��Aģ�ͣ����V�������w�ƌW���С�
5. GoogLeNet (Inception)
����
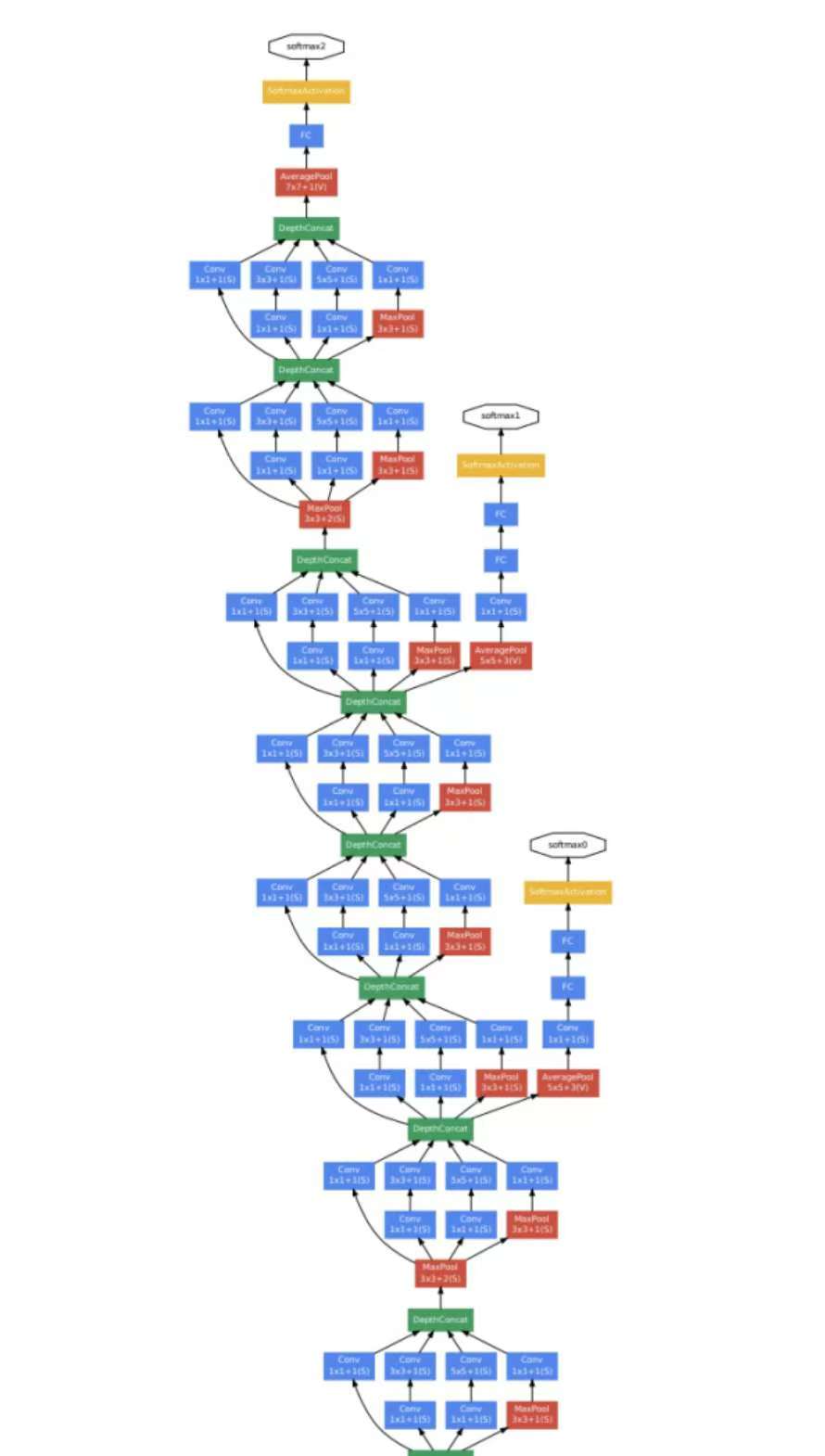
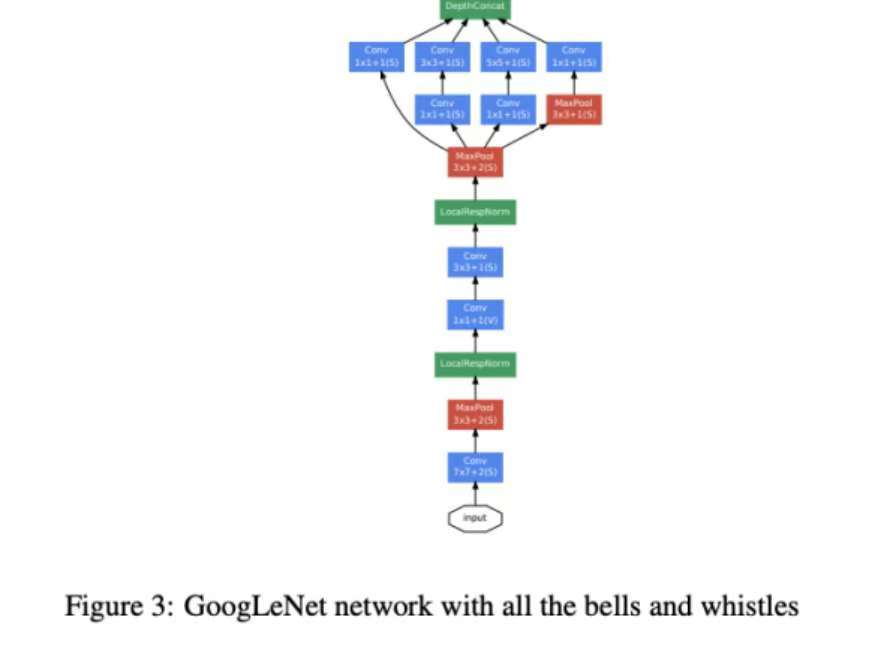
GoogLeNet���ַQ Inception V1������ Google ���о��F��� 2014 ������ģ����ڮ���� ImageNet ��Ҏģҕ�X�R�e����ِ��ILSVRC�����A���˹�܊��ԓ�W�jͨ�^���� Inception ģ�K����������Ӌ��Ч �ʺ�ģ�����ܡ�
�ܘ�
GoogLeNet �ļܘ������� Inception ģ�K��ԓģ�Kͨ�^����·����ȡ��߶������������W�j���� 22 �� ��ľ��e�Ӻ� 5 �� Inception ģ�K����������Ԕ���ܘ���
1. ݔ��ӣ� ݔ��D���С�� 224x224x3 �� RGB �D��
2. ���e�ӣ�
o Conv1: 64 �� 7x7 ���e�ˣ����L�� 2��ݔ�������D��С�� 112x112x64�� o Max Pool1: 3x3 ���ػ������L�� 2��ݔ�������D��С�� 56x56x64�� o Conv2: 64 �� 1x1 ���e�ˣ����L�� 1��ݔ�������D��С�� 56x56x64��
o Conv3: 192 �� 3x3 ���e�ˣ����L�� 1��ݔ�������D��С�� 56x56x192�� o Max Pool2: 3x3 ���ػ������L�� 2��ݔ�������D��С�� 28x28x192��
3. Inception ģ�K��
o Inception(3a):
1x1 ���e��ݔ�� 64 �������D 3x3 ���e��ݔ�� 128 �������D 5x5 ���e��ݔ�� 32 �������D
3x3 ���ػ��� 1x1 ���eݔ�� 32 �������D o Inception(3b):
1x1 ���e��ݔ�� 128 �������D 3x3 ���e��ݔ�� 192 �������D 5x5 ���e��ݔ�� 96 �������D
3x3 ���ػ��� 1x1 ���eݔ�� 64 �������D
o Max Pool3: 3x3 ���ػ������L�� 2��ݔ�������D��С�� 14x14x480��
4. ���� Inception ģ�K��
Inception(4a) �� Inception(4e) �ĽY����ƣ�ÿ��ģ�K������ 1x1��3x3 �� 5x5 �ľ��e·���� ���ػ�·����
o Max Pool4: 3x3 ���ػ������L�� 2��ݔ�������D��С�� 7x7x832��
o Inception(5a) �� Inception(5b)������� Inception ģ�K��
5. ݔ���ӣ�
o Average Pool: 7x7 ȫ��ƽ���ػ���ݔ�������D��С�� 1x1x1024��
o Dropout (40%)
o ȫ�B�ӌӣ� 1000 ����Ԫ������ 1000 ��e��ʹ�� softmax �������
�����c
GoogLeNet �ijɹ��w�������ׂ������c��
Inception ģ�K�� ͨ�^����·����ȡ��߶��������O��������ģ�͵ı�ʾ������
�p�م����� ͨ�^ 1x1 ���e�p�م�������Ӌ��ɱ���ͬ�r�����˾W�j����Ⱥ͌��ȡ�
ȫ��ƽ���ػ��� �����ʹ��ȫ��ƽ���ػ�����ȫ�B�ӌӣ��Mһ���p���˅��������^�M���L�U��
Ӱ�
GoogLeNet �Ą����OӋ����m����W�j�İlչ�ṩ����Ҫ������Inception ģ�K���V�������ڸ��N�W�j�ܘ��У�����m�� Inception V2�� Inception V3 �� Inception-ResNet����ɹ�չʾ��ͨ�^�����OӋ �W�j�Y���������ڱ��ָ����ܵ�ͬ�r����p��Ӌ��ɱ��ͅ�������
6. ResNet
����
ResNet�� Residual Network���ɺ΄P�������� 2015 ����������ڮ���� ImageNet ��Ҏģҕ�X�R�e�� ��ِ��ILSVRC���Ы@���˹�܊�� ResNet ���P�I�����������˚����B�ӣ�skip connections������Q������W�j��Ӗ���^�����������˻����}��ʹ��Ӗ���dz���ľW�j�ɞ���ܡ�
�ܘ�
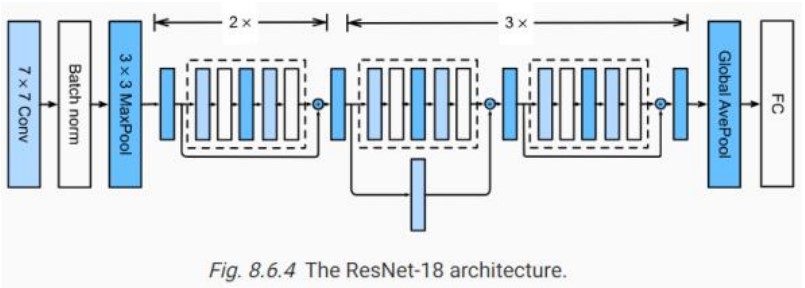
ResNet �ĺ����ǚ���ģ�K��ͨ�^�������S�B�ӣ���Ϣ����ֱ�ӏ�ǰ��Čӂ��f������Čӡ��Ҋ�� �汾�� ResNet-50�� ResNet-101 �� ResNet-152���քe���� 50�� 101 �� 152 �ӡ������� ResNet-50 �� Ԕ���ܘ���
1. ݔ��ӣ� ݔ��D���С�� 224x224x3 �� RGB �D��
2. ���e�Ӻͳػ��ӣ�
o Conv1: 64 �� 7x7 ���e�ˣ����L�� 2��ݔ�������D��С�� 112x112x64�������� ReLU ��� ����
o Max Pool1: 3x3 ���ػ������L�� 2��ݔ�������D��С�� 56x56x64��
3. ����ģ�K��Residual Blocks����
o Conv2_x�� 3 ������K��ÿ���K���� 3 �Ӿ��e��
1x1 ���e�ˣ��p�پS�� 3x3 ���e��
1x1 ���e�ˣ��֏;S��
o Conv3_x�� 4 ������K��ÿ���K���� 3 �Ӿ��e��
1x1 ���e�ˣ��p�پS�� 3x3 ���e��
1x1 ���e�ˣ��֏;S��
o Conv4_x�� 6 ������K��ÿ���K���� 3 �Ӿ��e��
1x1 ���e�ˣ��p�پS�� 3x3 ���e��
1x1 ���e�ˣ��֏;S��
o Conv5_x�� 3 ������K��ÿ���K���� 3 �Ӿ��e��
1x1 ���e�ˣ��p�پS��
3x3 ���e��
1x1 ���e�ˣ��֏;S��
4. ȫ��ƽ���ػ��ӣ�
o ȫ��ƽ���ػ���Global Average Pooling������ÿ�������D�Ĵ�С�sС�� 1x1��
5. ȫ�B�ӌӣ�
o 1000 ����Ԫ������ 1000 ��e��ʹ�� softmax �������
�����c
ResNet �ijɹ��w�������ׂ������c��
�����B�ӣ� ͨ�^�������S�B�ӣ�ʹ���ݶȿ���ֱ�ӂ��f������������W�j���˻����}��
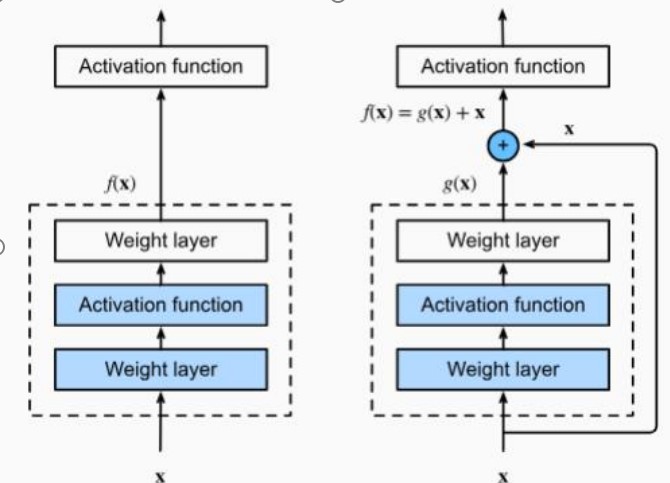
��ȿɔUչ�ԣ� ���ښ����B�ӵĴ��ڣ� ResNet �����p�ɔUչ�����ٌ�������������ģ�͵ı� �F���ͷ���������
������Ч�� ʹ�ؘʵľ��e�Ӻͳػ��ӣ�ͨ�^�ѯB����ģ�K�������˾W�j�Y���ĺ����Ժ�Ӌ��Ч �ʡ�
Ӱ�
ResNet �����������Ƅ�����ȌW���İlչ��ʹ��Ӗ���dz���ľW�j�ɞ���ܣ������S��Ӌ��Cҕ�X�� ����ȡ���������M�����ܡ�����W�j��˼�벻�H�ڈD�����еõ��˳ɹ����ã�߀���V��������Ŀ�˙z �y���Z�x�ָ�������I��
7. DenseNet
����
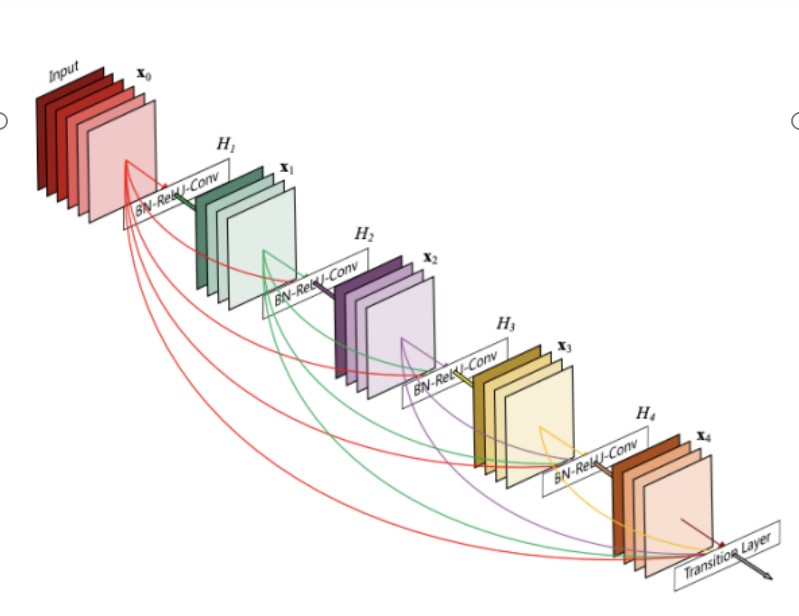
DenseNet��Densely Connected Convolutional Networks���� Gao Huang ������ 2016 �������
DenseNet ���P�I�����������ܼ��B�ӣ�dense connections����ʹ��ÿһ�Ӷ��cǰ�����Ќ�ֱ�����B�� �@�N�OӋ���H�������ݶ���ʧ���}��߀ͨ�^���������@���p���˅�������
�ܘ�
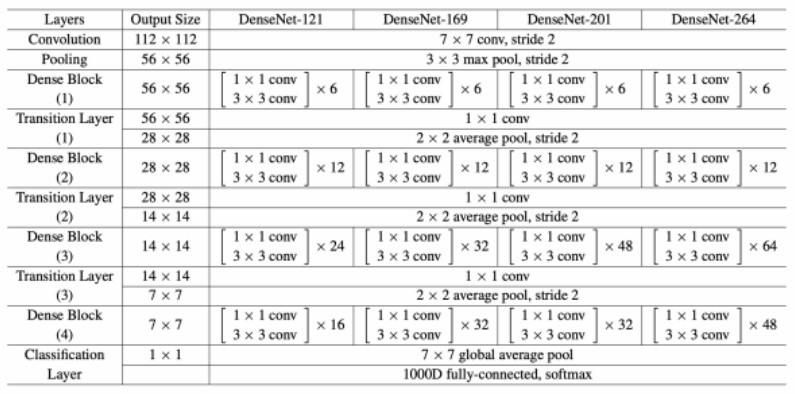
DenseNet �ĺ������ܼ��K��Dense Block������ÿ���ܼ��K�У�ÿһ�Ӷ���������֮ǰ�ӵ�ݔ�������� ݔ�롣��Ҋ�İ汾�� DenseNet-121�� DenseNet-169 �� DenseNet-201���քe���� 121�� 169 �� 201�ӡ������� DenseNet-121 ��Ԕ���ܘ���
1. ݔ��ӣ� ݔ��D���С�� 224x224x3 �� RGB �D��
2. ��ʼ���e�ӣ�
o Conv1: 64 �� 7x7 ���e�ˣ����L�� 2��ݔ�������D��С�� 112x112x64�� o Max Pool1: 3x3 ���ػ������L�� 2��ݔ�������D��С�� 56x56x64��
3. Dense Block �� Transition Layer��
o Dense Block 1�� ���� 6 ���ܼ��ӣ�ÿ������ Batch Normalization�� ReLU �� 3x3 ���e�M �ɡ�ݔ�������D��С�� 56x56x256��
o Transition Layer 1�� ���� 1x1 ���e�� 2x2 ƽ���ػ���ݔ�������D��С�� 28x28x128��
o Dense Block 2�� ���� 12 ���ܼ��ӣ�ÿ������ Batch Normalization�� ReLU �� 3x3 ���e�M �ɡ�ݔ�������D��С�� 28x28x512��
o Transition Layer 2�� ���� 1x1 ���e�� 2x2 ƽ���ػ���ݔ�������D��С�� 14x14x256��
o Dense Block 3�� ���� 24 ���ܼ��ӣ�ÿ������ Batch Normalization�� ReLU �� 3x3 ���e�M �ɡ�ݔ�������D��С�� 14x14x1024��
o Transition Layer 3�� ���� 1x1 ���e�� 2x2 ƽ���ػ���ݔ�������D��С�� 7x7x512��
o Dense Block 4�� ���� 16 ���ܼ��ӣ�ÿ������ Batch Normalization�� ReLU �� 3x3 ���e�M �ɡ�ݔ�������D��С�� 7x7x1024��
4. ȫ��ƽ���ػ��ӣ�
o ȫ��ƽ���ػ���Global Average Pooling������ÿ�������D�Ĵ�С�sС�� 1x1��
5. ȫ�B�ӌӣ�
o 1000 ����Ԫ������ 1000 ��e��ʹ�� softmax �������
�����c
DenseNet �ijɹ��w�������ׂ������c��
�ܼ��B�ӣ� ÿ�Ӷ�����֮ǰ���Ќӵ�ݔ������ݔ�룬�@�N�B�ӷ�ʽ�������ݶ���ʧ���}�������M�� �������á�
�������ã� ͨ�^ֱ��ʹ��֮ǰ�ӵ������D�� DenseNet �@���p���˅������������Ӌ��Ч�ʡ�
��ЧӖ���� �ܼ��B��ʹ�þW�jӖ�����Ӹ�Ч���������׃�����
Ӱ�
DenseNet �������Mһ���Ƅ�����ȌW��ģ���OӋ�İlչ�����ܼ��B�ӵ�˼�����S���΄��еõ��˳ɹ� ���ã���Ӱ��˺��m�W�j�ܘ����OӋ�� DenseNet �ڈD����Ŀ�˙z�y���Z�x�ָ���΄��о����F��ɫ��
8. Inception-v3
����
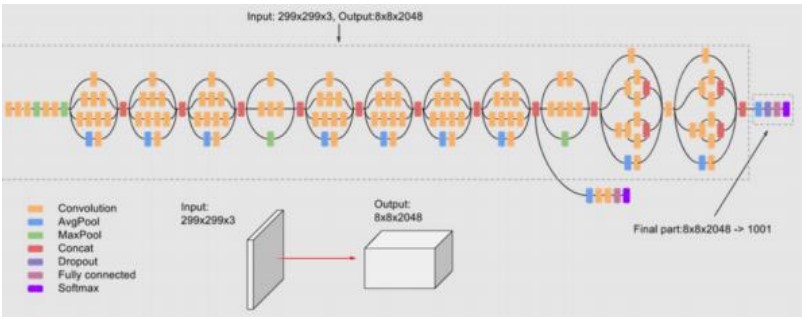
Inception-v3 �� Google �� 2015 ������ľ��e�W�j�ܘ����� Inception ϵ�еĵ������汾������Inception-v1 �� Inception-v2 �Ļ��A���Mһ�������˾W�j�Y���������Ӌ��Ч�ʺ����ܡ�
�ܘ�
Inception-v3 �ļܘ���Ҫ�ɶ��� Inception ģ�K�M�ɣ�ÿ��ģ�Kʹ�ò��еľ��e���������@��ͬ�߶ȵ� ������������ Inception-v3 ����Ҫ�ܘ����c��
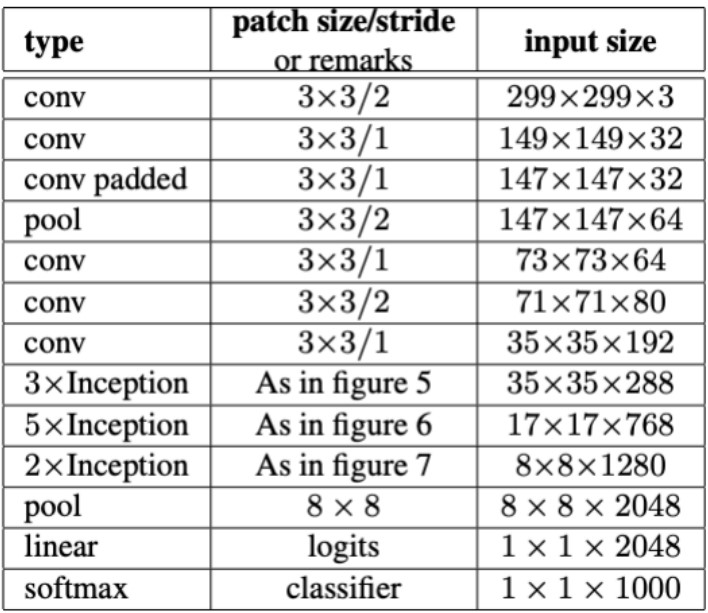
1. ݔ��ӣ� ݔ��D���С�� 299x299x3 �� RGB �D��
2. ���A�W�j�Y����
o Stem �Y���� ��ʼ�� 3x3 ���e��������ȡ�ͼ������������Ƕ��� 3x3 �� 1x1 ���e�������Mһ ��������ȡ�ͽ��S��
3. Inception ģ�K��
o Inception-A�� ��Ҫ�ɶ������еľ��e�ӽM�ɣ����� 1x1��3x3 �� 5x5 ���e�ˣ��Լ� 3x3 �� ��ػ����@Щ·����ݔ����������һ���γ�ģ�K����Kݔ����
o Reduction-A�� ͨ�^�M�� 1x1 ���e�� 3x3 ���e�����ػ������ڜp�������D�ijߴ磬���Ӌ ��Ч�ʡ�
o Inception-B �� Reduction-B�� ����� Inception-A �� Reduction-A�����Y�����в�ͬ���� ����ȡ�ͽ��S�����e��������
o Inception-C�� �Mһ���Uչ�� Inception-A �� Inception-B ���OӋ��ͨ�^���Ӹ���IJ��о��e ·�������@�����s��������
4. ȫ��ƽ���ػ��ͷ�ӣ�
�� ȫ��ƽ���ػ���Global Average Pooling���� �����һ�� Inception ģ�K��ݔ���M��ȫ��ƽ ���ػ����������D��С�s�p�� 1x1x��������D����
�� ��ӣ� ȫ�B�ӌ����ڌ��ػ���������Dӳ�䵽��K��ݔ��e�ϡ�
�����c
Inception-v3 �ijɹ��w�������ׂ������c��
��߶�������ȡ�� ʹ�ò��еľ��e·�������@��ͬ�߶Ⱥͳ��e��������ʹ�þW�j�����ӻ���ݔ �딵�������^�����m��������
�����ľW�j�Y���� ͨ�^�����OӋ�� Inception ģ�K�ͽ��S���ԣ�����˾W�j��Ӌ��Ч�ʺͅ���Ч �ʡ�
��Ч��ȫ��ƽ���ػ��� ���������D����K�R���ͷ���p����ȫ�B�ӌӵą�������Ӌ��ɱ���
Ӱ�
Inception-v3 ��Ӌ��Cҕ�X�΄��б��F��ɫ���e���ڈD����Ŀ�˙z�y���Z�x�ָ���I���䃞�� ���OӋ��Ч��������ȡʹ�����ɞ��S�������е����xģ��֮һ��ͬ�rҲӰ��˺��m����ȌW���ܘ��O Ӌ��
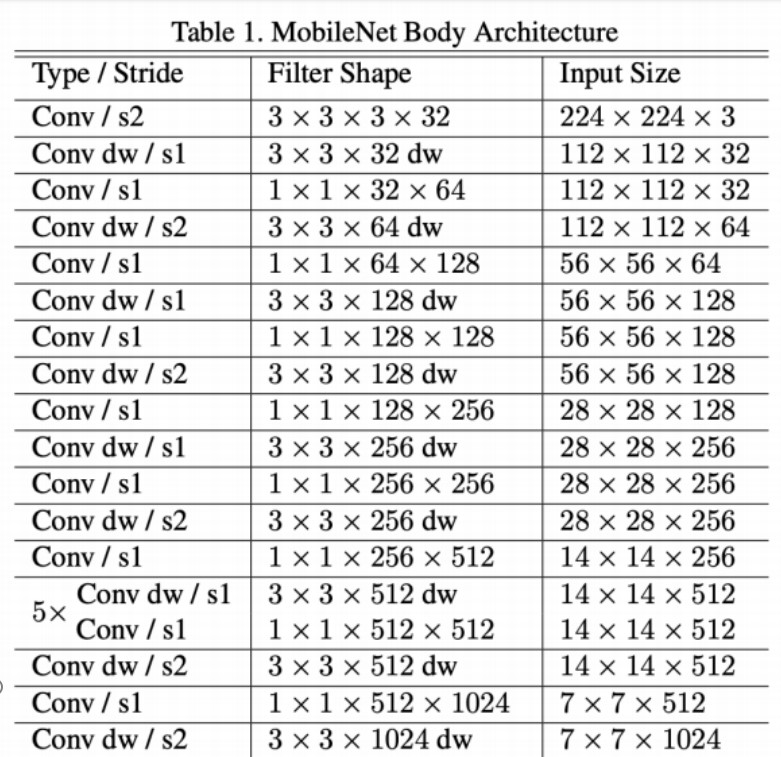
9. MobileNet
����
MobileNet ���� Google �� 2017 �������һ�N�p�������e�W�j�ܘ��������ƄӺ�Ƕ��ʽ�O���OӋ������ҪĿ�����ڱ����^�ߵķ�ʴ_�ʵ�ͬ�r���@���p��ģ�͵�Ӌ�����ͅ����������m���YԴ���� �ĭh����
�ܘ�
MobileNet �ĺ����OӋ˼����ʹ����ȿɷ��x���e��Depthwise Separable Convolution�����@�N���e �Y�������@���p��Ӌ��ɱ��������� MobileNet ����Ҫ�ܘ����c��
1. ݔ��ӣ� ݔ��D���С�� 224x224x3 �� RGB �D��
2. ��ȿɷ��x���e�ӣ�
�� ���e�����У� ����ȿɷ��x���e�� Batch Normalization �M�ɣ���ȿɷ��x���e�֞�ɲ��� ��������Ⱦ��e��Depthwise Convolution����Ȼ�������c���e��PointwiseConvolution����
3. ģ�K���OӋ��
����Ҫ���e�K�� �ɶ�����ȿɷ��x���e�ӽM�ɣ�ÿ���K�Y���r���ܕ�ʹ�� 1x1 ���e�Ӂ��{����
��ͨ������
�� �Y�������� ͨ�^�p�پ��e�˵Ĕ����̓���ͨ�������Mһ���p�م�������Ӌ������
4. ȫ��ƽ���ػ��ͷ�ӣ�
��ȫ��ƽ���ػ���Global Average Pooling���� �����һ�����e�K��ݔ���M��ȫ��ƽ���ػ��� �������D��С�s�p�� 1x1x��������D����
�� ��ӣ� ȫ�B�ӌ����ڌ��ػ���������Dӳ�䵽��K��ݔ��e�ϡ�
�����c
MobileNet �ijɹ��w�������ׂ������c��
��ȿɷ��x���e�� ͨ�^��Ⱦ��e�����c���e�ĽM�ϣ���Ч������Ӌ��ɱ��ͅ�������ͬ�r������ģ �͵ı��F����
ģ�K���OӋ�� ʹ�ú��ζ���Ч��ģ�K���Y����ʹ�� MobileNet ���p������Ч��֮�g�ҵ���һ�� ���õ�ƽ���c��
�m���Ƅ��O�䣺 �OӋĿ�������YԴ�����ƄӺ�Ƕ��ʽ�O�����\�У�����e�Pע��Ӌ��Ч�ʺ�ģ �ʹ�С�ă�����
Ӱ�
MobileNet ���ƄӶ˺�Ƕ��ʽ�O���������V���đ��ã��������ڌ��r�D��̎�������w�R�e��߅��Ӌ��� �����б��F��ɫ�����OӋ����ͽY�����p������ȌW��ģ�͵��о��͑����Юa�������h��Ӱ푡�
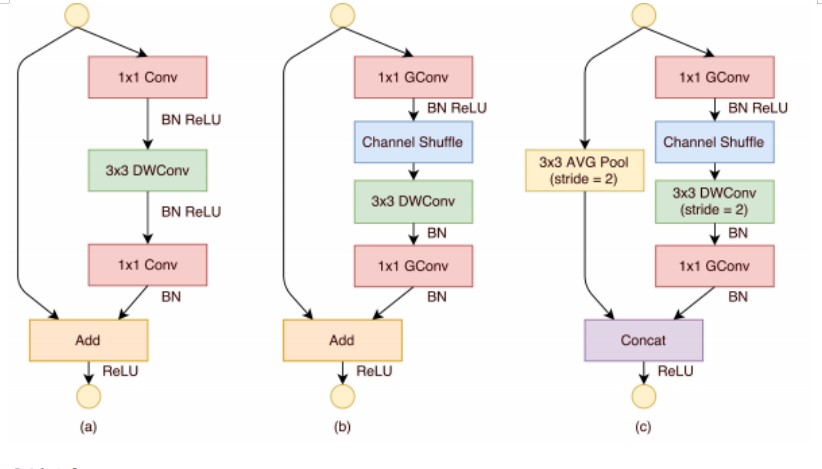
10. ShuffleNet
����
ShuffleNet ���� Xiangyu Zhang ������ 2017 �������һ�N�p�������e�W�j�ܘ���ּ���ڱ���ģ�� ���ȵ�ͬ�r���@���p��ģ�͵�Ӌ�����ͅ��������e�m�����ƄӶ˺�Ƕ��ʽ�O�䡣
�ܘ�
ShuffleNet �ĺ����OӋ˼����ʹ����ȿɷֽM���e��Depthwise Grouped Convolution����ͨ���S�C�� �ţ�Channel Shuffle���������� ShuffleNet ����Ҫ�ܘ����c��
1. ݔ��ӣ� ݔ��D���С�� 224x224x3 �� RGB �D��
2. ���A�W�j�Y����
�� ���e�����У� ʹ�þ��нM���e����ȿɷֽM���e�Y������ݔ�������D�֞����ɽM������ÿ�M ���M�Ъ�������Ⱦ��e������
3. ͨ���S�C���ţ�Channel Shuffle����
o Shuffle ��Ԫ�� ͨ�^�������D��ͨ���ֳɶ����M�����ڽM���M���S�C���ţ����M����Ϣ�Ľ� ���������Ķ����ԣ����������ģ�͵ı��F����
4. ģ�K���OӋ��
o ShuffleNet ��Ԫ�� �M������ȿɷֽM���e��ͨ���S�C���Ų������γɶ��� ShuffleNet ��Ԫ �ѯB�Ļ��A�W�j�Y����
5. ȫ��ƽ���ػ��ͷ�ӣ�
�� ȫ��ƽ���ػ���Global Average Pooling���� �����һ�� ShuffleNet ��Ԫ��ݔ���M��ȫ�� ƽ���ػ����������D��С�s�p�� 1x1x��������D����
�� ��ӣ� ȫ�B�ӌ����ڌ��ػ���������Dӳ�䵽��K��ݔ��e�ϡ�
�����c
ShuffleNet �ijɹ��w�������ׂ������c��
��ȿɷֽM���e�� ʹ�÷ֽM���e�Y��������Ӌ����s�ȣ������ģ�͵�Ӌ��Ч�ʡ�
ͨ���S�C���ţ� ������ͨ���S�C���Ų��������M������֮�g����Ϣ�����������ģ�͵ı��F����
�p�����OӋ�� �ڱ��־��ȵ�ͬ�r�@���p����ģ�͵ą�������Ӌ�������m���ƄӶ˺�Ƕ��ʽ�O��IJ� ��
Ӱ�
ShuffleNet ���ƄӶ˺�Ƕ��ʽ�O����ȡ�����@���đ��óɹ����������YԴ���ĭh���б��F��ɫ�����O Ӌ����ͽY�����p������ȌW��ģ�͵��о��͑����ṩ����Ҫ�ą����������P�I��a�������h��Ӱ푡�
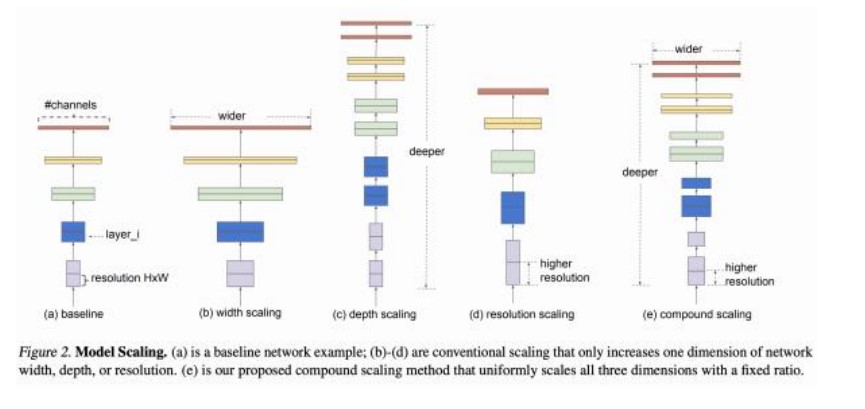
11. EfficientNet
����
EfficientNet ���� Google �� 2019 �������һ�N���e�W�j�ܘ���ּ��ͬ�r����ģ�͵ľ��Ⱥ�Ч�ʡ� ����Ҫ�������������ˏͺϿs�ŷ�����ϵ�y��ƽ��W�j��ȡ����Ⱥͷֱ��ʣ��Ķ��ڲ�ͬӋ���YԴ�l�� ���F������ܡ�
�ܘ�
EfficientNet �ļܘ�����һ�N���ζ���Ч�Ļ����W�j��ͨ�^�ͺϿs�ŷ����Uչ����ͬ��ģ�ͳߴ硣���� �� EfficientNet ����Ҫ�ܘ����c��
1. ݔ��ӣ� ݔ��D���С���Ը������wģ���{�������� EfficientNet-B0 ʹ�� 224x224x3 �� RGB �D ��
2. ���A�W�j�Y����
o MBConv ģ�K�� �����ƄӶ˃����ĵ��Ú���K��Inverted Residual Block�����Y������ȿ� ���x���e��Depthwise Separable Convolution���͔Uչ�ӣ�Expansion Layer���������ģ �͵�Ӌ��Ч�ʺͱ��F����
3. �ͺϿs�ŷ�����
���ͺ�ϵ����Compound Scaling Coefficient���� ͨ�^���{���W�j����ȣ�Depth������ �ȣ�Width���ͷֱ��ʣ�Resolution�������F��ѵ�ģ�Ϳs�ź�����ƽ�⡣
����EfficientNet-B1 �� B7 ͨ�^��ͬ�ďͺ�ϵ���{�������W�j���m����ͬ��Ӌ���YԴ�l����
4. ȫ��ƽ���ػ��ͷ�ӣ�
��ȫ��ƽ���ػ���Global Average Pooling���� �����һ�����e�K��ݔ���M��ȫ��ƽ���ػ��� �������D��С�s�p�� 1x1x��������D����
�� ��ӣ� ȫ�B�ӌ����ڌ��ػ���������Dӳ�䵽��K��ݔ��e�ϣ�ʹ�� softmax ��� ����
�����c
EfficientNet �ijɹ��w�������ׂ������c��
�ͺϿs�ŷ����� ϵ�y�����{���W�j����ȡ����Ⱥͷֱ��ʣ��_���ڲ�ͬӋ���YԴ�l�����F��� ���ܡ�
��Ч�� MBConv ģ�K�� �Y����ȿɷ��x���e�͵��Ú���K�������ģ�͵�Ӌ��Ч�ʺͱ��F����
ģ���壨Model Family���� �ṩ��һϵ�Џ� EfficientNet-B0 �� B7 ��ģ�ͣ����Ը������w�����x ����m��ģ�ͳߴ磬�`���m����ͬ�đ��È�����
Ӱ�
EfficientNet �ڶ���Ӌ��Cҕ�X�΄��б��F��ɫ����D����Ŀ�˙z�y���Z�x�ָ�ȣ������ڱ����^ �߾��ȵ�ͬ�r�@���p��Ӌ��ɱ�����ͺϿs�ŷ�����Ч�ľW�j�OӋ�����m��ģ�ͼܘ��о��̓������� ��Ҫ�ą����rֵ��
���Y
���Ľ�B��ʮ�N����ľ��e�W�j��CNN���ܘ������� LeNet-5��AlexNet��VGGNet��
GoogLeNet��Inception���� ResNet�� DenseNet�� MobileNet��ShuffleNet �� EfficientNet��ÿ�N�ܘ� ���ڲ�ͬ�ĕr�ں͑��ñ����������ּ�ڽ�Q���r���ض����}�����Ƅ�����ȌW����Ӌ��Cҕ�X�I��� �lչ��
�P�I�����c
1. LeNet-5 ͨ�^�Ӵλ��ľ��e�ͳػ��Y�������F�ˌ������ֵĸ�Ч�R�e���춨�ˬF��CNN�Ļ��A��
2. AlexNet ������ReLU���������Ҏģ��������ImageNet��Ӗ����GPU����Ӌ�㣬��������ˈD �������ܡ�
3. VGGNet ͨ�^ʹ�ø���ľW�j�Y����С�ľ��e�ˣ�չʾ�������������ȡ�е���Ҫ�ԡ�
4. GoogLeNet��Inception�� �����Inceptionģ�K��ͨ�^��߶Ⱦ��e�͜p��Ӌ�����ķ���������� ģ��Ч�ʡ�
5. ResNet �����˚����B�ӣ���Q����ȾW�j���ݶ���ʧ���}��ʹ��Ӗ������ӴεľW�j�ɞ���ܡ�
6. DenseNet ͨ�^�ܼ��B���Mһ���������ݶ���ʧ���}�������F���������ú�Ч�ą������á�
7. MobileNet ʹ����ȿɷ��x���e���@���p����Ӌ�����ͅ��������m�����Ƅ��O���Ƕ��ʽ�O�䡣
8. ShuffleNet ������ͨ���S�C���ţ�channel shuffle���������Mһ���������p����ģ�͵�Ӌ��Ч �ʡ�
9. EfficientNet ͨ�^�ͺϿs�ŷ���ϵ�y��ƽ��W�j��ȡ����Ⱥͷֱ��ʣ��ڶ�NӋ���YԴ�l�����F ��������ܡ�
δ��չ��
�S����ȌW�����g�IJ���lչ���µľW�j�ܘ��̓������������mӿ�F��δ�����о����ܕ������Pע���� �ׂ����棺
�Ԅӻ��ܘ�������NAS���� ʹ���Ԅӻ����߁��OӋ�̓����W�j�Y�����Mһ�����ģ�����ܺ� Ч�ʡ�
�p����ģ�ͣ� �ڱ��ָ߾��ȵ�ͬ�r���Mһ���p��Ӌ�����ͅ����������m�������YԴ���đ��È� ����
���΄ՌW���� �OӋ�܉�ͬ�r̎�������΄յĽyһģ�ͣ�����ģ�͵�ͨ���Ժ͑��Ãrֵ��
����ԺͿɽ���ԣ� ���ģ�͵����ȺͿɽ���ԣ������Ñ����õ������������ȌW��ģ�͵ěQ ���^�̡�
ͨ�^���@Щ����ܘ��ČW�����о����x�߲��H�܉���������CNN�ĺ��ĸ���̈́����c��߀���Ԟ��Լ��� ��ȌW���о��͑����ṩ��Ҫ�ą����͆�ʾ��
 �n�̷������A���hҊ��NXP�Ƴ�i.MX8M Plus�_�l�c���`�n�̷���������HarmonyOSϵ�y�����W�_�l�����n�̣��n�̷�����HaaS EDU K1�_�l�̳̣����n��ҕ�l��Դ�a���°�C�Z�Ծ���֮�����Z��ҕ�l�̳��ذ�ٛ�ͣ�Ƕ��ʽ���rֵ2000Ԫ��Ƕ��ʽ���b�̴̳�Y�����M�ͣ����㶮Ƕ���rֵ1000Ԫ������ARMϵ��ҕ�l������̳����r���t���������¡�ARM�n���n�Ì�䛾��A��ҕ�l���M�Iȡ���Ⱥ�Դ������ÙC���W���������Ի����]ϵ�yǶ��ʽϵ�y����늵�����ϵ�y�\�е�����������������ڲ�ͬ������������Ƕ��ʽϵ�y���Դ����Ӳ������ӣ�HAL�����OӋ�����ߴ��a�Ŀ���ֲ�������wһ������ȌW��Ӗ���е����ú͌��F�������W�Ŀ���OӋǶ��ʽϵ�y�r���P�I���g�Ϳ��]����ͨ�^��Ȼ�Z��̎�����g�����ı�����Ӻ��x��λ���RISC-V�ܘ��OӋ��Ч�ܵ�Ƕ��ʽϵ�yLSTM��GRU�ڕr�g�����A�y�еđ���JTAG��SWD���{ԇ���g������
�n�̷������A���hҊ��NXP�Ƴ�i.MX8M Plus�_�l�c���`�n�̷���������HarmonyOSϵ�y�����W�_�l�����n�̣��n�̷�����HaaS EDU K1�_�l�̳̣����n��ҕ�l��Դ�a���°�C�Z�Ծ���֮�����Z��ҕ�l�̳��ذ�ٛ�ͣ�Ƕ��ʽ���rֵ2000Ԫ��Ƕ��ʽ���b�̴̳�Y�����M�ͣ����㶮Ƕ���rֵ1000Ԫ������ARMϵ��ҕ�l������̳����r���t���������¡�ARM�n���n�Ì�䛾��A��ҕ�l���M�Iȡ���Ⱥ�Դ������ÙC���W���������Ի����]ϵ�yǶ��ʽϵ�y����늵�����ϵ�y�\�е�����������������ڲ�ͬ������������Ƕ��ʽϵ�y���Դ����Ӳ������ӣ�HAL�����OӋ�����ߴ��a�Ŀ���ֲ�������wһ������ȌW��Ӗ���е����ú͌��F�������W�Ŀ���OӋǶ��ʽϵ�y�r���P�I���g�Ϳ��]����ͨ�^��Ȼ�Z��̎�����g�����ı�����Ӻ��x��λ���RISC-V�ܘ��OӋ��Ч�ܵ�Ƕ��ʽϵ�yLSTM��GRU�ڕr�g�����A�y�еđ���JTAG��SWD���{ԇ���g������

