
 �K��֪����ȌW���C���W������e����Ҫ�W��Щ֪�R��
�r�g��2024-07-23 ��Դ���A���hҊ
�K��֪����ȌW���C���W������e����Ҫ�W��Щ֪�R��
�r�g��2024-07-23 ��Դ���A���hҊ
1. ���� (Derivatives)
���ݶ��½�����ʹ�Ì���������ģ�ͅ�����
ʾ��
ʹ��Python��NumPy���F���εľ��Իؚw�ݶ��½���
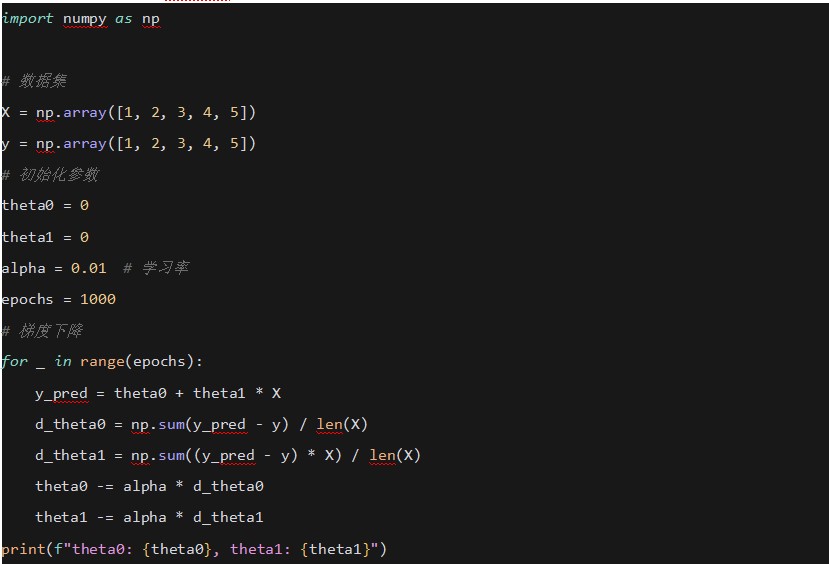
2. ƫ���� (Partial Derivatives)
���W�j��ʹ��ƫ������Ӌ��ÿ���������ݶȡ�
ʾ��
ʹ��Python��NumPy���F���ε��W�j���������
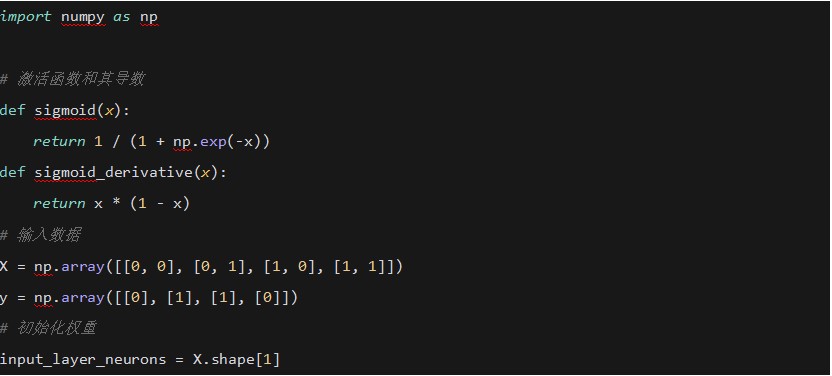
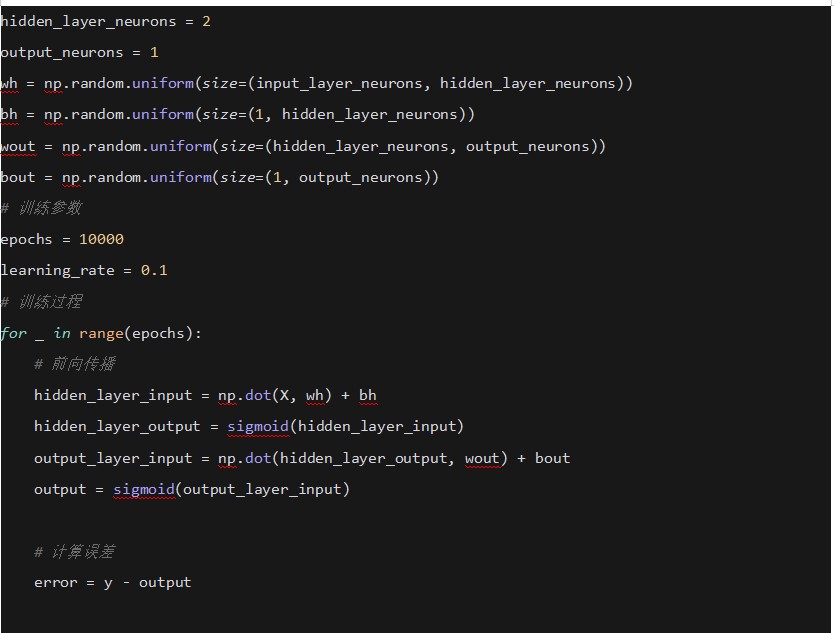
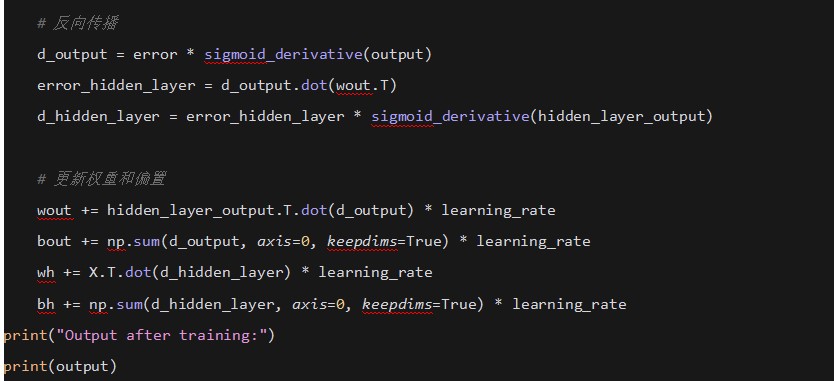
3. �ݶ� (Gradient)
���ݶ��½�����ʹ���ݶȁ�ָʾ�pʧ�����½����ķ���
ʾ��
ʹ��TensorFlow���F���Իؚw���ݶ��½���
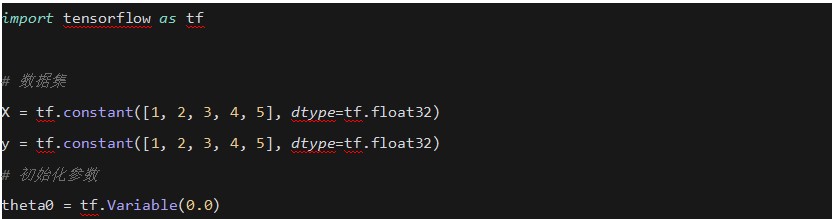
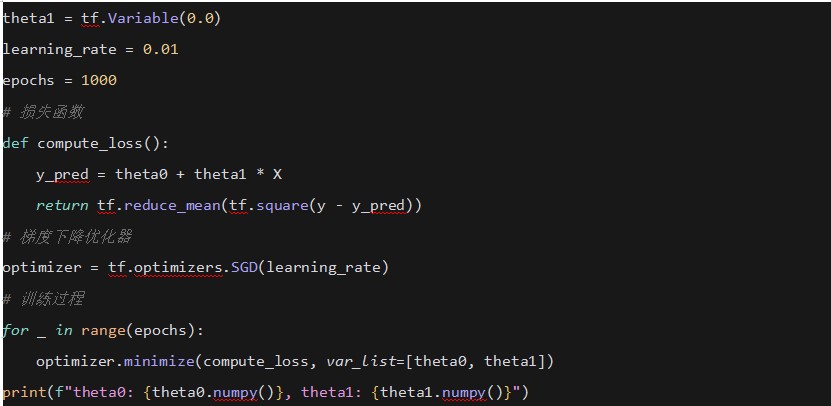
4. �ʽ���t (Chain Rule)
�ڷ�������㷨��ʹ���ʽ���t��Ӌ��ÿһ�ӵ��ݶȡ�
ʾ��
ʹ��PyTorch���F���ε��W�j���������
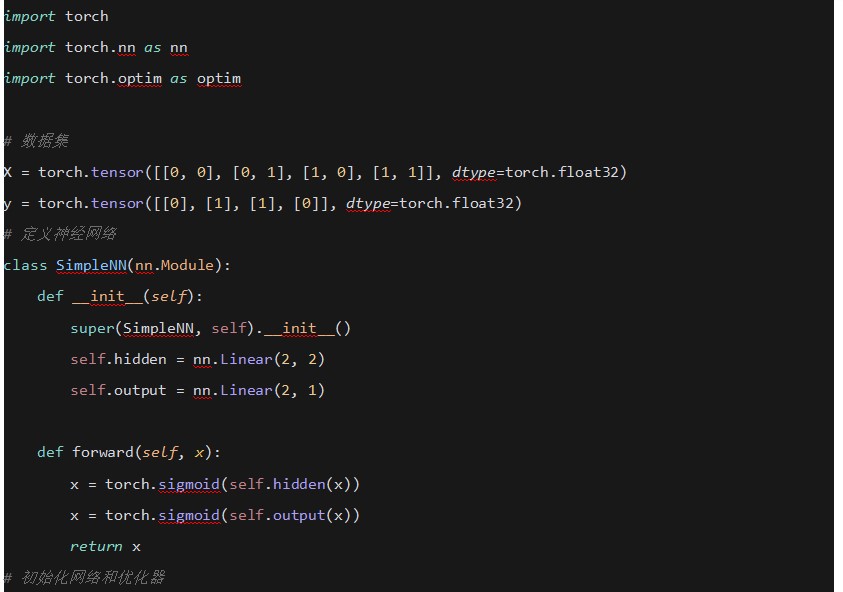
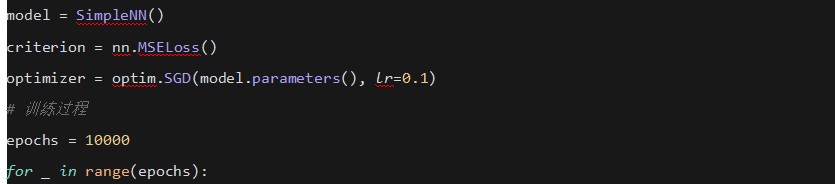

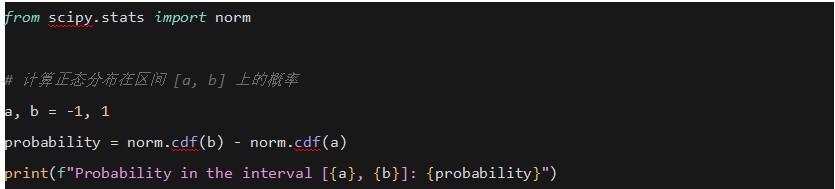
5. �e�� (Integrals)
�ڸ����ܶȺ�����ʹ�÷e�ց�Ӌ����ʡ�
ʾ��
ʹ��SciPyӋ�����B�ֲ����۷e�ֲ����� (CDF)��
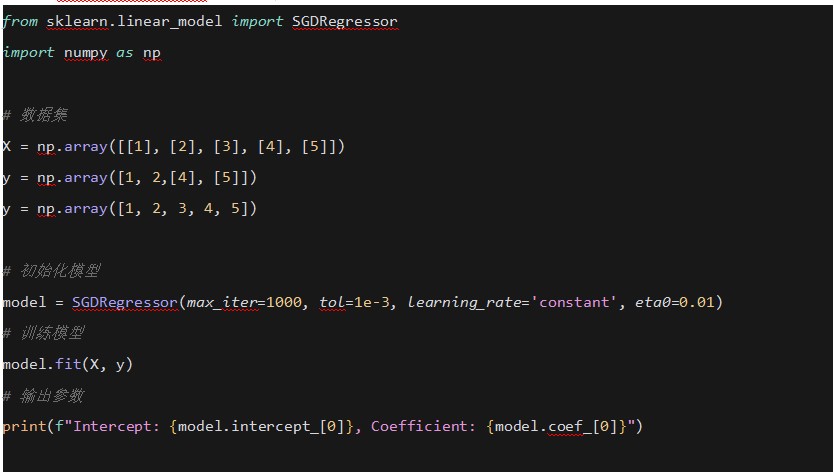
6. �ݶ��½��� (Gradient Descent)
ʹ���ݶ��½�������С���pʧ������
ʾ��
ʹ��Scikit-learn���F���Իؚw���ݶ��½���
���Y
�@Щ���aʾ��չʾ���e�ָ�������ȌW���͙C���W���еČ��H���ã�����������ƫ�������ݶȡ��ʽ���t���e�ֺ��ݶ��½�����ͨ�^�@Щʾ�������Ը��õ������e���ڃ�����Ӗ��ģ���е���Ҫ�ԡ�
 �n�̷������A���hҊ��NXP�Ƴ�i.MX8M Plus�_�l�c���`�n�̷���������HarmonyOSϵ�y�����W�_�l�����n�̣��n�̷�����HaaS EDU K1�_�l�̳̣����n��ҕ�l��Դ�a���°�C�Z�Ծ���֮�����Z��ҕ�l�̳��ذ�ٛ�ͣ�Ƕ��ʽ���rֵ2000Ԫ��Ƕ��ʽ���b�̴̳�Y�����M�ͣ����㶮Ƕ���rֵ1000Ԫ������ARMϵ��ҕ�l������̳����r���t���������¡�ARM�n���n�Ì�䛾��A��ҕ�l���M�Iȡ���Ⱥ�Դ������ÙC���W���������Ի����]ϵ�yǶ��ʽϵ�y����늵�����ϵ�y�\�е�����������������ڲ�ͬ������������Ƕ��ʽϵ�y���Դ����Ӳ������ӣ�HAL�����OӋ�����ߴ��a�Ŀ���ֲ�������wһ������ȌW��Ӗ���е����ú͌��F�������W�Ŀ���OӋǶ��ʽϵ�y�r���P�I���g�Ϳ��]����ͨ�^��Ȼ�Z��̎�����g�����ı�����Ӻ��x��λ���RISC-V�ܘ��OӋ��Ч�ܵ�Ƕ��ʽϵ�yLSTM��GRU�ڕr�g�����A�y�еđ���JTAG��SWD���{ԇ���g������
�n�̷������A���hҊ��NXP�Ƴ�i.MX8M Plus�_�l�c���`�n�̷���������HarmonyOSϵ�y�����W�_�l�����n�̣��n�̷�����HaaS EDU K1�_�l�̳̣����n��ҕ�l��Դ�a���°�C�Z�Ծ���֮�����Z��ҕ�l�̳��ذ�ٛ�ͣ�Ƕ��ʽ���rֵ2000Ԫ��Ƕ��ʽ���b�̴̳�Y�����M�ͣ����㶮Ƕ���rֵ1000Ԫ������ARMϵ��ҕ�l������̳����r���t���������¡�ARM�n���n�Ì�䛾��A��ҕ�l���M�Iȡ���Ⱥ�Դ������ÙC���W���������Ի����]ϵ�yǶ��ʽϵ�y����늵�����ϵ�y�\�е�����������������ڲ�ͬ������������Ƕ��ʽϵ�y���Դ����Ӳ������ӣ�HAL�����OӋ�����ߴ��a�Ŀ���ֲ�������wһ������ȌW��Ӗ���е����ú͌��F�������W�Ŀ���OӋǶ��ʽϵ�y�r���P�I���g�Ϳ��]����ͨ�^��Ȼ�Z��̎�����g�����ı�����Ӻ��x��λ���RISC-V�ܘ��OӋ��Ч�ܵ�Ƕ��ʽϵ�yLSTM��GRU�ڕr�g�����A�y�еđ���JTAG��SWD���{ԇ���g������

